This Acoustics FAQ — with an emphasis on music acoustics — began because questions about sound are often sent to our music acoustics web site. See also the Basics section of the music acoustics web site. If your question isn't answered below, or in the Basics section, send it to J.Wolfe@unsw.edu.au.
How can you have negative decibels?
Doesn't zero decibels mean no sound?
Zero decibels is a reference level, not zero sound pressure. So one can have negative decibels. Zero dB is usually set at about the limit of human hearing (in the most sensitive frequency range). The sound level in dB is a measure (on a logarthmic scale) of the ratio of the sound pressure or sound intensity to this reference level. The logarithm of one is zero, so zero dB corresponds to the reference level. Numbers greater than one have positive logarithms, so positive decibels means sound levels greater than that of the reference. Numbers smaller than one have negative logarithms, so negative decibels mean sound levels below the reference level.
Zero sound pressure or zero sound intensity would actually be minus infinity dB. However, it is impossible to reduce the sound pressure and sound intensity to zero, unless you go to a vacuum, because of the thermal motion of molecules.
What is the relation between loudness and decibels? Is 80 dB twice as loud as 40 dB? How do you translate from decibels to loudness?
Sound level in dB is a physical quantity and may be measured objectively. Loudness is a perceived quantity and one can only obtain measurements of it by asking people questions about loudness or relative loudness. (Of course different people will give at least slightly different answers.) Relating the two is called psychophysics. Psychophysics experiments show that subjects report a doubling of loudness for each increase in sound level of approximately 10 dB, all else equal. So, roughly speaking, 50 dB is twice as loud as 40 dB, 60 dB is twice as loud as 50 dB, etc. The units of loudness determined in this way are sones.
This relation implies that loudness and intensity are related by a power law: loudness in sones is proportional to (intensity)log 2 = (intensity)0.3.
For more details, see the page devoted to the decibel scale in which the relationships among sound intensity, sound pressure, dB, dBA, sones and phons are explained. We also have a web service with which you can measure your own hearing response curve.
Does adding two identical sounds give an increase of 3 dB or 6dB? Why?
A subtle question: if you look at the page What is a decibel?, you'll see that doubling the sound pressure gives an increase of four in the intensity, so an increase in the sound level of 6 dB, whereas doubling the power increases the intensity by a factor of two, so an increase of 3 dB. There is no paradox here, because to double pressure and to double power you do two different things. Let's see how, starting with a simplified system.
Let's imagine that we have a completely linear amplifier and speaker.
If we double the voltage at the input (like adding two identical voltage signals), the we double the voltage to our linear loudspeaker and thus double the sound pressure it puts out, which gives us four times as much energy, four times as much intensity everywhere in the sound field, and thus a uniform increase in sound level of 6 dB. (The amplifier is also delivering four times as much electrical power.)
Now imagine that
we have two identical, linear amplifiers and speakers, and we'll forget about reflections from walls, floor etc. We put the same signal into the inputs of both. Now each amplifier is producing the same amount of electrical power, so the output sound power is only doubled. On average, the intensity in the sound field is only doubled. Let's consider just a single sine wave (or, if you like, one frequency component of the sound). If your ear is equidistant from the two speakers, then the two pressure waves will add in phase (constructive interference), so the sound pressure at your ear will be twice as great, so you'll a level 6 dB higher when the second amplifier is turned on. However, if you are half a wavelength further from one speaker than from the other, then two pressure waves will add one half cycle out of phase (destructive interference) and the sound pressure will be zero. So the sound intensity is four times as great in some places, zero in others, and intermediate values in most places. Integrate this over all space and the total power is only doubled.
This diagram plots the sound pressure (as a function of x and y but not z) from two identical sources separated by three wavelengths. This is an example of Young's experiment.
What if the sounds are not identical, but have the same level? Then the phase difference will be random. If two signals have pressure amplitude pm and a phase difference θ, then their sum is pm(1+cosθ), which varies from 0 to 2pm as a function of θ. But the power is proportional to the amplitude squared, and so proportional to pm2(1+cosθ)2. The average of (1+cosθ)2 over all θ is 2 so the average of the whole term over all possible phase differences is 2pm2. So again, on average we double the power and so get an increase of 3 dB in sound level.
How does a wall make things louder? (One of the laws of busking.)
Imagine that a source of sound with power P is sitting on hard ground, in the open air, radiating sound uniformly in all directions. Let's assume that the ground absorbs no sound. Now draw a hemisphere
centred on this source, with radius r. All of the power P passes through the surface of the hemisphere, whose area is 2πr2. So the intensity at distance r is I = P/2πr2. Let's now move the source against a perfectly reflective wall: it's now radiating through a quarter-sphere, with area πr2, so its intensity (P/πr2) has been increased by a factor of 2, so the sound level is increased by 3 dB. Now move into a corner, still on the ground. The power now passes through one eighth of a sphere, so intensity is now another factor of 2 higher, and the sound level increased by further 3 dB, which is 6 dB higher than the open air.
Okay, now what about if you're not on the ground? Then we run into inference and filtering, which are discussed above. For sufficiently long wavelengths (low frequencies) the '3 dB for a wall' still works, but it becomes more complicated for high frequencies. Further, some surfaces absorb high frequencies more than low, so the high frequency gain may not be as high.
I've been asked about the other laws of busking. Well I've not busked for quite a while but some of the important things are (2) smile, energy and eye contact (look like you're having fun), (3) duos and (4) nucleation. Why duos? My experience is that a duo makes more than twice as much. Partly because of the interaction: there's something good and live going on betweenthe two of you, and passers-by find that interesting, even enviable. Further, it's easier to keep your energy and spirits up, and easier to take a breather. Nucleation: if you can get three people to stop, others are more likely to stop. ('Hey, this must be worth stopping for'.) If you can ask friends or family to drop by and stop for a while to nucleate a crowd, it can be really helpful. Conversely, if you like a busker, then stopping to help nucleate might be more valuable than any coins you can spare.
What is the loudest sound?
Atmospheric pressure is about 100 kPa. So, in air at normal pressure, one cannot have a symmetric wave whose pressure amplitude exceeds 100 kPa, because one cannot have a negative pressure in a gas. (One can, however, have negative absolute pressures in liquids.) A peak of 100 kPa in a sine wave corresponds to a pressure amplitude of 70 kPa rms, which in turn corresponds to a sound level of 191 dB (see What is a decibel? for details). You could get a few more dB by making the hypothetical signal a square wave, but it won't be square for long. An asymmetric signal such as a single compressive pulse could, in principle, have a larger amplitude than this. Pulses with amplitudes comparable with 100 kPa quickly distort as they travel. Very close to an explosion, for instance, the sound pressure in the shock wave could exceed 100 kPa. If you know the peak pressure Pp in kPa, you can estimate the sound level as 20 log(35,000,000*Pp/kPa) dB. As to what such a sound might sound like... well, you'd be deaf afterwards. How much damage it does to you (would you explode during the rarefaction?) depends on frequency and duration, but you'll probably be dead, too.
For sound in liquids and solids, higher intensities and much higher sound pressure levels are possible.
For every 10 m of extra depth underwater, you raise the static pressure by one atmosphere. Further, sound levels are usually measured with respect to 20 µPa (see What is a decibel? for details). A wave transmitting the same power in a liquid or a solid has a much higher sound pressure level in dB than one in a gas.
(See Acoustic impedance, intensity and power) for details.)
Why do cathedrals (and many other large, enclosed spaces) have long reverberation times?
Clap your hands: soon it is silent. So, where does sound energy go?
In a room, if there is an open window or door, some sound energy goes outside. Any other part of the room's boundary reflects some of the sound back into the room and absorbs the rest. Acoustic tiles and soft furnishings absorb much more than does a hard, massive surface like a stone wall. The cathedral has good reflecting walls and few open windows or doors – also (ask someone who prays a lot) not enough cushions!
But there is another important effect. Sound energy is stored in the air, but absorbed at the surface. Usually, a large hall has a much greater ratio of volume to surface area. So, a large volume stores more sound energy than a small one. A large room has a higher volume:area ratio than a small one of the same shape. The rate at which sound energy is lost therefore scales as one over the linear dimension of the room, all else equal.
The reverberation time measures how long takes to 'fade away'. Usually, it's quantified as the RT60, which is the time for a very brief sound to decay by 60 dB, or to lose 99.9999% of its sound energy. (see What is a decibel? for the energy to dB calculation.)
Wallace Sabine showed that the decay is approximately exponential and calculed the RT60 using what we know as the Sabine equation:
The RT60 is a fraction of a second in a normal room, but
can be several seconds in a cathedral because the big volume of the cathedral stores more sound energy, and the waves don't often encounter a surface, especially an absorbing one. You'll even notice the difference between an empty house and a furnished one: furniture has a lot of surface area, much of it absorbing. This equation is only approximate. (For example, try putting zero absorption in.) So it's worth mentioning that, even if the walls were perfectly reflecting, the reverberation time would be finite, because some energy is lost in transmission. See Why is sound absorption in water less than in air?
for an explanation.
What is acoustic impedance and how is it related to intensity?
Acoustic impedance Z is the ratio of the acoustic pressure p, measured in Pascals, to the acoustic volume flow, measured in cubic metres per second. Specific acoustic impedance z is the ratio of the acoustic pressure p, measured in Pascals, to the acoustic velocity, measured in metres per second. We introduce and explain these in two separate pages. Acoustic impedance, intensity and power is (a section in) an introduction in terms of physics and the wave equation. What is acoustic impedance? explains it for musicians and explains how and why the acoustic input impedance is used to characterise wind instruments.
Why is sound absorption in water less than in air? According to my text, for a 1 kHz signal in water the loss by medium absorption is about 0.008 dB/100 m. In air, the loss is much greater: about 1.2 dB/100 m. Why is this?
Imagine that we could take a very fast picture of certain properties of a sound wave during transmission. The pressure varies from a little above atmospheric, to a little below and back again as we progress along the wave. Now the high pressure regions will be a little hotter than the low pressure regions. The distance between two such regions is half a wavelength: 170 mm for a wave at 1 kHz in air. A small amount of heat will pass from hot to cold by conduction. Only a very small amount, because, after half a cycle (0.5 milliseconds for our example), the temperature gradient has reversed. Although it is small, this non-adiabatic (non-heat conserving) process is responsible for the loss of energy of sound in a gas.
What happens when we change the frequency? The heat has less distance to travel (shorter half wavelength), but less time to do so (shorter half period). These two effects do not cancel out because the time taken for diffusion (of heat or chemical components) is proportional to the square of the distance. So high frequency sounds lose more energy due to this mechanism than do low. This, incidentally, is one of the reasons why we can tell if a known sound is distant: it has lost more high frequency energy, and this contributes to the 'muffled' sound. (Another contributing effect is that the relative phase of different components is changed.)
So, let's now dive into the main question. Three different parameters make the loss less in water.
First, sounds travels several times faster in water than in air. (Although the density of water is higher by a factor of about 800, the elastic modulus is higher by a factor of about 14,000.) So, for a given frequency, the wavelength is longer and the heat has further to travel.
Second, the water does not conduct heat so rapidly as does air. (This may seem odd if you've recently dived into cold water, but the effect in that case is largely due to water requiring more heat for the same temperature change. Not counting the fact that you probably wear more clothes when out of the water.)
Third, the temperature of water rises less under a given imposed pressure than does that of air.
All three effects go in the same direction, and their cumulative effect is substantial, as your text's values suggest.
Why do the sounds of two musical instruments always reinforce, and never cancel out? According to the interference of waves, two waves with exactly the same amplitude and frequency can either reinforce (if they are in phase) or cancel (if 180� out of phase). However, when two instruments play the same note, it is always louder, and never softer. Why?
The answer to this involves several different effects that complicate the sound of musical instruments. To hear the effect of destructive interference, you have first to eliminate each of these effects, and it is rare that they are all eliminated together, which is why you don't normally hear destructive interference in practice. Nevertheless, when two instruments are nearly but not exactly in tune, you do hear the phenomenon of beats (listen to the sound files of beats). This is an example of constructive and destructive interference: the slight difference in frequency causes the phase relationship to change slowly. When the two waves are in phase it sounds loud but, when they are out of phase it is soft.
Beats between real musical instruments do have variation in loudness, but the loudness doesn't usually go to zero. There are several reasons for this:
First, real musical instruments rarely have exactly equal amplitude, so even when they are exactly out of phase, their waves don't cancel. (And they often have vibrato.) Even if they were of equal amplitude, it is unlikely that you would be equally distant from both. Further, this effect is enhanced by the logarithmic response of your ears (see what is a decibel? for details). If two waves cancel to 99%, the resulting sound is 40 dB softer than one instrument alone. Listeners often judge that 40dB softer sounds about 1/16 as loud. So even if you achieve cancellation with this precision (hard to do), the effect is not as spectacular as you might expect.
Second, real musical instruments don't play sine waves: =they have several harmonics. Even when the conditions are such that two harmonics cancel, other harmonics may not.
Third: unless you are in an anechoic chamber, the points of cancellation are not where you calculate them to be, because of multiple reflections off walls.
Fourth: you have two ears. Even if one ear is at the point of cancellation, the other is not.
Fifth: your ears are most sensitive in the range 1-4 kHz, which means wavelengths of ~300 mm to ~100 mm. Nearly all instruments radiate fairly strongly in this range, so you must get cancellation in this frequency range to get cancellation. However, because of these short wavelengths the region of cancellation (if there is one, in spite of the complications mentioned above) is very small, and the chance of having even one ear at the point is small.
Sixth: instruments and peoples ears move on a scale of at least tens of mm (often more) during performance.
Despite all of the above, it is possible to set up conditions under which you can experience the interference effects. Simply set up a sine wave source (eg an electronic tuner) in a room. There will be reflections off walls and other objects that cause the amplitude to vary strongly from place to place. Cover one ear, put the other near a wall, and move your head towards and away from it. If you were to drive two identical speakers with the same signal but reversed in phase, and if you did it in an anechoic chamber, then you should get cancellation on the plane of symmetry between the speakers. If you put one ear on this plane, and neglecting the reflections from your body, you'd expect to get pretty good cancellation. (I've never tried this experiment in an anechoic chamber, but I've certainly noticed the effect of reflections from walls.)
However,
even in that extreme condition with two identical sine wave sources, cancellation is restricted to a small fraction of the space. Suppose that we add two signals of amplitude A and with phase difference π + φ, where φ is small: near but not quite cancelling.
The amplitude of the resultant is
approximately Aφ. So, to get cancellation of down to A/10 in amplitude (a 26 dB reduction from the maximum amplitude of 2A), we need −0.1 < φ < 0.1. The chance of that happening is 0.2/2π = 3%.
(Phasor diagrams are useful for calculating the combined amplitude and power of signals with relative phase.)
In Berio's Sequenza VII, a sine wave is played throughout on the note B4. It creates an eery ambiance: one doesn't know where it is coming from and it seems to get louder and softer, for several of the reasons discussed above, including the motion of performer and audience.
When music is recorded with two or more microphones,
it occasionally happens that two microphones give signals
for one instrument that substantially reduces, by phase
cancellation, one or more harmonics. Mixing desks often
have a switch that allows the operator to reverse the
phase of a channel to reduce this problem.
How does active noise cancellation work? And where
does the sound energy that gets cancelled end up? More
specifically: when I wear those active headphones, the speakers
put sound into the headphone and this cancels out the noise
from outside. But now there is a bit more sound energy than
there was before: the sound energy that was there, plus
the energy from the loudspeakers in the headphone. Where
does it go?
The short answer is that it goes somewhere else: outside
the ear enclosures. Let's see how. I'll only talk about
low frequencies, because active noise cancellation only works at 'low' frequencies. If your ear enclosure has only one speaker, then it will only work for wavelengths much bigger than the enclosure: let's say wavelengths much bigger than 80 mm, which means frequencies no higher than a few hundred hertz. We'll see why later. I'm also simplifying considerably.
The first picture below shows an ear enclosure that seals well around the ear, but which lets sound in because it is not completely rigid. It deforms a little (in the sketch, the 'little' has been enormously exaggerated) and so the air inside the enclosure is alternately compressed and expanded, so your ear is exposed to a varying pressure, and you hear a sound. This is the sound that has been transmitted through the enclosure by deforming it. The sound that is not transmitted into the enclosure, is reflected. Here, the reflected sound is less than the incident sound, as indicated by the size of the arrows.
The second picture shows a hypothetical ear enclosurethat is perfectly rigid and that makes a perfect seal around your ear. This doesn't transmit sound into the inside: the air inside is neither compressed nor expanded, so you don't hear a sound. Because no sound is transmitted in, it must all be reflected. This means that the sound level outside the rigid enclosure is slightly higher than that outside the deformable one, because the reflected signal is stronger.
The third picture shows a simplified schematic of an enclosure with active noise cancellation. A microphone converts the sound pressure into a voltage, passes it to an amplifier and loudspeaker whose combined gain is negative, i.e. it is 180� out of phase with the microphone. This negative gain ensures that the loudspeaker makes a sound signal just strong enough to cancel out the signal at the microphone. So the pressure in the enclosure doesn't vary, and you hear no sound. However, if the pressure inside is not varying, the air inside cannot be undergoing compressions and expansions. So that means that the enclosure is not moving in response to the sound wave from outside. The effect of the speaker and cancellation network is to make the enclosure behave as though it were completely rigid.
(Technically we could say that it has changed the acoustic impedance of the enclosure, as measured from outside, infinite, compare to the lower value it had when it was deformable.) If we compare the first and third pictures, we now see the effect of turning on the noise cancellation: it makes the enclosure behave as though it were rigid, and it reflects more sound, so that's where extra sound that didn't come through the enclosure has gone: outside.
This still leaves the problem: if the second and third diagrams produce the same sound outside, what happened to the sound energy you put in with the loudspeaker? The answer is a little surprising. The work done by a moving object like a loudspeaker is the integral of the force it applies (here pressure times area) over the distance travelled. Neglecting the energy absorbed by the microphone, this is actually zero in the simplified case studied here. The loudspeaker may use up electrical power, but it doesn't transmit any sound power. (In the real world, the speakers do transmit a tiny amount of power, both forwards and backwards. And of course you'll still have to replace your batteries from time to time: amplifiers use up energy just by being switched on.)
Notice that I have spoken of the pressure inside the enclosure, as though it had a single, value--the same everywhere. This is only true if the wavelength of the sound is much greater than the size of the enclosure, and that explains the limited frequency range of this technique. At high frequencies, the cancellation may work close to the microphone, but not elsewhere.
Comparing the second and third pictures invites a final question: if a perfectly rigid ear enclosure keeps all the sound out, why bother with active noise cancellation in this application? First, perfectly rigid enclosures that make perfect seals against the head do not exist. However, modestly priced hearing enclosures can often reduce sound by more than 30 dB, and this is better than the only active headphones that I have tried. Further, the hearing protectors work up to higher frequencies. So for serious hearing protection they are recommended. The advantages of the active devices are that they are sometimes more comfortable (eg on hot days) and that you can immediately plug them into a sound channel. For instance, they are widely used by pilots who can then listen to radio or other communications in a noisy cockpit. Hearing protectors require modifications to function as headphones. (However, there may be a market for a comfortable, rigid hearing protector with loudspeakers inside and which are not coloured safety orange.)
How does the Doppler effect affect the player and the audience? Since the sound is traveling away from the player, should the player perceive the pitch as lower than somebody in the audience?
There is no such effect for the player. The Doppler effect arises where there is relative velocity between the observer's ears and the sound source. Even if you have a really weird performance technique, the relative velocity between your ears and your instrument is much less than the speed of sound! If the player or the audience were moving there would be such an effect for the audience, but they'd have to run or bicycle for it to be an important effect. In normal listening circumstances, the sound from the instrument goes towards your ears and the audience's ears at the same speed.
Incidentally, one might expect a perceptible Doppler effect in the 'bull roarer'*, an instrument used by (among others) some of the first nation peoples of Australia. This instrument is swung around the head on a cord at high speed. However, other periodic effects in its sound tend to complicate perception of the Doppler effect here.
* The users don't call the instrument a 'Bull roarer', but the proper names for it are only shared with male initiates, so this author does not know them.
What are those sounds (such as telephone ring tones) that kids can hear but adults cannot?
High frequencies. Almost always, adults lose the sensitivity to high frequencies first. It is not well known how much of this is due to age and how much is due to lifetime exposure to noise, because the two are correlated. Children may hear sounds above 20 kHz, but adults rarely can. In middle or old age, the upper frequency limit gradually descends.
You can find out how well you hear different frequencies -- including your high frequency limit -- on our web service Test your own hearing. In fact, that site may be where some youngsters are downloading their high frequency sounds.
Why does helium (balloon gas) make your voice sound strange?
First, a warning: helium is suffocating and breathing it could be fatal. See Helium inhalation – it's no laughing matter. In order to hear the effect, a single shallow breath is sufficient.
The frequency of your voice is not much changed by inhaling some helium. The resonances of the vocal tract, and hence usually the formants, are moved to higher frequency. This makes a substantial difference to the sound spectrum of the voice. Its effect is somewhat similar to that of a high pass filter (there are some filter sound file examples on our page about filters). Do either of these change the pitch? Or do they change some other aspect of the voice? Or both? Your answer to this question might depend on whether you listen to speech or to sung notes. We've put up some sound files and an explanation at Helium speech .
A horn seems to amplify in both directions: as an old hearing aid, or old gramophone. How?
Before electronics, a large horn could be used as a hearing aid: the small end was placed at the ear, and the large end pointed towards the sound source. A similar horn was used in a gramophone: the small end was connected to the needle, and sound radiated from the large end. Yes, the horn works in both cases and I can understand why you say that it amplifies in both directions. First, however, let's define amplification.
An electronic amplifier takes an electrical signal with low power as input, and outputs a signal with high power. The horn does not amplify in this sense: the output signal does not have more power than the input signal.
So what does the horn do?
Technically, the horn in each case is an impedance matcher. Let's think of the hearing aid use. Sound in the air (a medium with low density) has relatively small pressure variation, and relatively large oscillatory flow of air. Your inner ear is full of liquid (whose density is 800 times greater) and vibrations in this medium require relatively large pressure variation, and relatively low oscillatory flow of liquid. In healthy ears, the outer and middle ear serve to convert the wave in the air (low pressure, high flow) to a wave in the liquid (high pressure, low flow). The horn does the same thing: from large end to small, it 'concentrates' the wave so that higher pressure is exerted at the small end. However, the power is the pressure times the flow, so the power can be the same at both ends. (In practice, of course, there are losses.)
In the case of the gramophone, the vibrating needle vibrates with relatively large force, but it is so small that it doesn't move much air. So it is connected to a diaphragm at the small end of the cone, and exerts a substantial force on it. This creates a wave with high pressure and low flow at the small end of the horn.
Technically, we say that the horn matches a high acoustic impedance at the small end to a low acoustic impedance at the large end.
The electronic analogue of this is the transformer: it takes in high voltage and low current at one end, and delivers low voltage and high current at the other (or vice versa). Neither the horn nor the transformer amplify power.
Incidentally, the bell on a brass instrument most obviously works as an impedance matcher for sound going outwards. Because it works best for high frequencies, it has important effects for the loudness and timbre of brass instruments. It also works as an impedance matcher for sound going inwards, which sometimes has deleterious effects for the player, as we explain on this page about timpani-horn interactions.
How does a Helmholtz resonance 'amplify' sound in a guitar or violin, but also muffle sounds, as in architectural acoustics applications?
This question has some similarities with the one above, and the scare quotes around 'amplify' are appropriate for the same reason: the Helmholtz resonance is passive and so does not amplify anything in the physical sense. Rather, it enhances transmission or reduces losses by what we call impedance matching. The Helmholtz resonance for a guitar or violin works for frequencies near that of the second lowest string and a little above and below. These are low pitches and relatively long wavelength sound waves � much longer than the instrument. At these frequencies, the instrument body vibration doesn�t couple well to the radiation field of the air. The Helmholtz resonance alternately squeezes and expands the air in the body, pumping air in and out of the sound hole of the guitar or the f-hole of the instrument. This is a strong source of sound and makes the instrument louder and 'bassier' over a narrow band of notes. (More here, including demonstrations.)
So far, we�ve considered air flow coming out of the resonator and radiating as a sound wave. Now consider the reverse: imagine that a sound wave comes towards a wall made up of guitars, side by side. This new 'wall' will reflect less power than a solid wall, because incoming sound waves, at frequencies near the Helmholtz resonance, will excite that resonance, pumping air in and out through the sound hole. This causes a varying pressure inside, which moves the walls slightly. Both the passage of air through the sound hole and the moving wood take power out of the sound wave. If we add absorbing material we can take more out. So the wall of H resonators removes energy and lowers reflection. (In architectural acoustics, walls of guitars are not used. Panels are made with very many small Helmnoltz resonances.) To lower reverberation in a room, even a small percentage of energy lost in each reflection makes a significant difference, because in a reverberant room any wave makes many reflections with each wall.
Vinyl or digital? Which has the better sound?
A vinyl phonograph record has an oscillating groove in which a needle vibrates as the record turns. For the same sound level, the vibrations of the needle at low frequency have a larger amplitude than those at high frequency. The maximum possible vibration amplitude is limited by the need to pack successive turns of the groove closer together and for mechanical reasons. Consequently, the low frequencies have to be attenuated and/or the high frequencies boosted when recording phonograph records. In the reproduction system, filters are used to reverse this effect. The reversal is never complete, so the signal reproduced from a phonograph recording always has some filtering, which is not usually present in digital recordings.
Which has higher fidelity? Usually, the answer is digital. But which is better? A lot of people prefer music with the phonograph distortion present, so for these people, vinyl is better, because of the lower fidelity. Fortunately, it is possible to reproduce phonograph distortion digitally and some digital sound systems allow one to reproduce the vinyl sound from a digital recording. Here is a link to an interview on the topic from my colleague John Smith.
Space isn't quite empty. Can it transmit sounds?
This question is more subtle than it appears. Sound is carried by pressure waves. Imagine the variations in pressure in a sound wave in air: a pressure maximum occurs where the density is highest. Due to molecular collisions, molecules tend to move from high to low pressure. That, plus the momentum of the molecules, produces the wave.
Pressure, however, is a macroscopic concept. We don't talk of the pressure of a few molecules, we talk about the forces that molecules exert during interactions. To talk of pressure, we need a significant number of molecules. In space, to have a considerable number of molecules/ atoms/ ions, you have to consider large volumes.
First let's consider just the atoms and molecules in space. The typical distance between them is about a centimetre. So we need a large volume to have a significant number. But it's more subtle than that. A sound wave propagates by intermolecular (or interatomic) collisions. Molecules in air only travel a nanometre or so (their mean free path) before they collide. What is the mean free path (m.f.p.) in space? Just from dimensional considerations, we can guess that it is roughly
(There's also a numerical factor in there, of order 1, but we shan't need it for this approximate calculation.)
So, taking the atomic area as ~ 10−20 m2, and number density (using the separation value quoted above) ~ 106 molecules m−3, we get a m.f.p. of about 1014 m or 0.01 light years. Collisions are rare. So, to talk of sound waves, we'd need to consider wavelengths of longer order than this. Very low frequencies.
In a plasma, things are more complicated, because the ions interact by electric and magnetic fields. (Strictly, I don't know whether a pressure wave in a plasma should be called a sound wave, but let's not quibble.) However, while the medium was a plasma, the radiation and matter were strongly coupled, so the temperature of the radiation was about the same as that of the matter.
The speed of sound is roughly proportional to the square root of the ratio of the temperature to the atomic or molecular mass. In the early universe, temperatures were very high and, early enough, the speed of sound was comparable with the speed of light!
As the universe itself expanded, the wavelengths of the pressure variations of the early universe have been expanded by a similar factor – and complicated by gravity. While the universe was a plasma, and the photons and the massive particles were strongly coupled. When it was about 400,000 years old, it was cool enough (a few thousand kelvin) for atoms (mainly hydrogen) to form, the universe became transparent and the photon and baryon density fluctuations thereafter expanded independently. Both, of course, have now ultralow frequencies. They are the subject of intense cosmological research. The photon density variations are present in the cosmic microwave background (CMB). The wavelength of these (electromagnetic) waves has also expanded, which is why it is now microwaves rather than light. Most of the ordinary matter has formed stars and their density variations (called baryon acoustic oscillations waves) are studied using telescopes. (Who'd have thought to use the telescope as a microphone?)
Both types of waves are of interest to cosmologists, including Mark Whittle of the University of Virginia. He came to our lab to talk about it and one of the postdocs here, Alex Tarnopolsky, made some sound files for him and transposed them up into the audible range. Mark now uses it in his seminars and calls it the "primal scream of the infant universe".
You can hear the first million years (transposed upwards by 50 octaves) on his website, where he has a rather nice popular account of these acoustics aspects of cosmology.
How much sound comes from the fusion of black holes?
Although there is no material medium, gravitational waves do distort space itself with a series of contractions and extensions. And LIGO's famous black hole fusion event of 2016 had an intensity level of 103 dB. Still, we didn't hear it—for interesting reasons. A colleague and I wrote a whimsical paper for Nature Physics about this.
And I've also posted an approximate calculation of the intensity using Newtonian physics rather than general relativity.
General questions in music acoustics
When we were playing two recorders, we heard a low buzzing sound, sometimes making a chord with our notes. What is that?
It is called the Tartini tone. It is most often noticeable when the two notes being played are sustained, about equally loud, not too low in pitch (say treble clef and above) and moderately loud. I've put a section about it on a page called Interference beats and Tartini tones where you can hear sound files made with pure sine waves that show the effect quite well. There is also a page called Tartini tones and temperament: a musician's introduction.
If you listen for the Tartini tone, you can use it to tune your chords: the tuning you will arrive at is Just Intonation, and not Equal Temperament. In sustained chords, the former usually sounds better.
(A multimedia introduction is at Tartini tones, consonance and temperament.)
The effect may be due to nonlinear effects (heterodyning) in the ear, or perhaps due to higher processing in the auditory cortex, or (more likely, I think) both of these.
The strong Tartini tone that we sometimes hear is usually generated in the ear. In the case of the two recorders (above), there is no vibration in the air at the difference frequency. However, when two notes are played simultaneously on the same instrument -- as played here on a violin by John McLennan -- it is possible to produce a difference tone via non-linearities in the instrument. This is explained in more detail in Interference beats and Tartini tones and in Tartini tones and temperament: a musician's introduction.
What are heterodyne and comination tones? How do they relate to beats and difference tones? And where do they come from?
Nonlinear systems, in response to two signals with frequencies f and g, produce heterodyne or combination signals, with frequencies mf +/- ng, where m and n are integers. To me, the two terms have the same meaning, although heterodyne is used more frequently in radio and TV.
One of the heterodyne terms, that with frequency f-g, is called the difference tone in acoustics and the Tartini tone in music. (I'm choosing f > g.) If (f-g) is rather smaller than f or g, then the phenomenon is called interference beats or just beats: the combined signal is an oscillation with frequency (f+g)/2, amplitude modulated by the beat frequency (f-g). When the beat frequency is less than a dozen Hz or so, it can be clearly heard as a variation in amplitude, and is commonly used to tune instruments. (Beats at mf-ng are also thus used.) See Interference beats and Tartini tones for examples and sound files.
Where do such terms come from?
Non-linear systems inherently produce them. I shan't go through the algebra here (though it's not difficult) but one can expand a non-linear response using a Taylor series. The series includes higher order terms, which become more important as the signals get larger. Simple trigonometric identities substituted in the product terms give the heterodyne terms.
In electronics, the nonlinear response of diodes was traditionally used for modulation and demodulation (producing heterodyne terms).
In music, nonlinearities occur in several places. The basilar membrane in the inner ear is nonlinear, and it is plausible that Tartini tones are generated here. I have read, however, that Tartini tones can be heard when one note is input to one ear and another to the other, via headphones. I've not experienced this myself but, if it happens, it suggests that they are produced in the neural processing. (Neural processing is highly nonlinear.)
They may also be produced in a nonlinear source. For instance, when they are produced by double stopping on a string instrument, one would expect the two notes to interact through the hair of the bow and through the bridge. The bow-string interaction is highly nonlinear, so this can produce heterodyne terms. This is shown in the example given above. When wind players produce multiphonics, they also produce heterodyne signals. To take one particular example that we have studied in detail: when a didjeridu player vocalises at a pitch different from that of the drone he is playing, strong heterodyne terms are produced.
Finally, it is possible to produce heterodyne terms in a microphone. No microphone is perfectly linear and so sufficiently strong signals could, in principle, produced heterodyne terms in the microphone itself.
Tartini tones sound unusual because one doesn't have a sense of direction associated with them. One can imagine that they are being produced 'inside one's own head', which may in fact be true. However, it's worth noting that, even in a slightly reverberant space, the same may be said of a pure tone. Listen to the sound files on Interference beats and Tartini tones and see if you agree.
What is the frequency, and how does it relate to pitch? Where do harmonics fit in? Does the frequency of the lowest harmonic determine the pitch?
The frequency f is the number of vibrations per unit time. For example, when a tuning fork sounds the note A4, its tines vibrate 440 times per second. Its frequency f is 440 cycles per second, which is usually written as 440 Hertz or 440 Hz. (The unit of frequency is named for Heinrich Hertz, a pioneer of electromagnetic radiation.) The pitch of a musical note is mainly determined by the frequency of its sound wave.
Pitch differences depend on the ratio of frequencies. If the frequency is doubled, the pitch rises by an octave, independent of starting frequency. If it increases by a factor of 3/2, the pitch rises by a fifth. (It follows that pitch is proportional to the logarithm of the frequency.)
The duration of each cycle of a vibration is called its period, T. If there are f cycles in one second, then each cycle must last 1/f seconds. In other words, the frequency is the reciprocal of period, or f = 1/T. So, for the note A4 at 440 Hz, the period is 2.27 milliseconds.
Musical tones usually comprise vibrations that are periodic. Such tones may be considered as the sum of pure tones from the harmonic series. So a note with frequency f usually contains also components with frequencies 2f, 3f, 4f etc. These components are called harmonics and the component with frequency f, the highest common factor, is called the fundamental. This is discussed in more detail in What is a sound spectrum?
We usually hear a pitch corresponding to the fundamental. However, we hear that pitch even if the fundamental is absent -- called the missing fundamental. For periodic tones, our sense of pitch is determined by the spacing of harmoncs in the region of several hundred Hz. So, for example, a small loudspeaker is very inefficient at 40 Hz. Consequently, when the sound of a bass playing its lowest note (E1 at 40 Hz) is played on such a speaker, the radiated sound has strong high harmonics, but almost no fundamental. Nevertheless, the pitch we hear is E1. The radiated sound might include the tenth, eleventh, twelfth etc harmonics at 400, 440, 480 Hz etc, and the spacing between these is 40 Hz.
What is all the fuss about temperament? Is it just an academic problem for musicologists? And what does it have to do with the circle of fourths?
Litres of ink have been spilt on this topic, and I expect that there are many web sites. But it is by no means a purely academic problem, so let me give a quick introduction. For example, suppose a violist tunes up nice pure fifths C3, G3, D4, A4, removing interference beats as he does so. These will give intervals with frequency ratios of 3:2. The violinist tunes in unison to the last three of these notes, ie G3, D4, A4, but then adds E5. So the ratio of the frequency of the violinist's E string to the violist's C is (3/2)*(3/2)*(3/2)*(3/2) = 5.063. If they played these open strings together it would sound (to many people, anyway) uncomfortably out of tune. The fifth harmonic of C3 at 5.000 times the fundamental clashes and produces beats with the open E5 at 5.063 times that fundamental. Of course in practice, while the violist must play the C3 as an open string, the violinist will rarely play E5 on open string, so in musical context the violinist solves it by adjusting the position on the fingerboard and/or adding some vibrato (or by glaring at the violist!).
Wind and bowed string instruments can rapidly change the pitch by changing embouchure or finger position respectively and so, for sustained chords, can tune to eliminate beats or to achieve some other effect. A harpsichordist or a pipe organist does not have the option of changing the pitch (quickly) according to harmonic context. For these instruments, one must make a compromise between getting nice fifths and nice thirds. Not all organists, and very few harpsichordists, think that equal temperament is a sufficiently good compromise for music containing thirds because it favours the fifths far too much at the expense of the thirds. Just intonation is no good if you go beyond the home key, and even within that key the chord on the second note of the scale is very ugly.
Mean tone temperament gets the thirds right, and this spreads the dissonance over four perfect fifths. (e.g. tune C3 - E5 in the ratio 5:1 and make the fifths equal to the fourth root of 5, which is 1.495, which is close to the just fifth of 1.500. This is acceptable in itself, but it becomes much worse if you modulate into different keys.
A harpischordist might get away with mean tone thus: put all pieces in the sharp keys in the first half of the concert and then retune during interval to play the pieces with flats in the second half.
Many people opine that the best compromises are the so-called Well-temperaments like those of Vallotti & Young and those of Werckmeister, which spread the dissonance over more fifths. Some musicologists think that Bach wrote the Preludes and Fugues to demonstrate one of the Well-temperaments, perhaps Werckmeister.
Why don't pianists and guitarists bother with temperament?
Wind and bowed string instruments have nearly *exactly* periodic sounds, and thus their partials are almost exactly harmonic. For these instruments, equal tempered thirds in sustained chords don't sound great.
Some guitarists possibly do use equal temperament. Others can adjust the tuning according to the key that they are to play in, and can do so quickly. They may use several different temperaments without noticing it.
Some good players clearly do adjust the tuning by pushing the finger that stops one string parallel to the string, so as to increase or to decrease its tension.
Pianos have strong transients, which mean that they don't have periodic sounds. Further, they have three strings for most notes, and these are tuned slightly differently (to assist sustain) which gives chorus effects that disguise the problem. There is the further complication that the partials of thick steel strings are sharper than harmonics and thus their sounds are not exactly harmonic. Try it on a guitar using the very high harmonics, particularly with solid steel strings.
Pianists get used to equal temperament, and may even prefer it to others, but string quartets sometimes have trouble playing quintets with piano.
So what of harpsichords? They have thinner, softer strings than do pianos and so their partials are more nearly harmonic. Also, harpischord players are more likely to have studied different temperaments, and are more likely to be playing with wind and string players who are conscious of the issues.
The frequency ratio of octaves on a piano are found to be slightly greater than 2:1, especially for the very high and very low notes, and especially for small pianos. The reason for this is that the octaves are usually tuned to eliminate interference beats between the fundamental of the upper note and the second partial (or resonance frequency) of the lower note. The second resonance of a struck string usually has a frequency that is slightly higher than twice that of the first, because of the finite bending stiffness of the string.
Playing an instrument that only sounds one note at a time, or singing, many musicians stretch octaves. However, playing chords with other instruments, they usually play 2:1 octaves.
What causes broadening or finite width of harmonic peaks in a Fourier transform?
If a signal is perfectly periodic (i.e. repeats exactly after a period T) and infinitely long, we might expect its Fourier transform to have infinitey narrow peaks at frequency f = 1/T and the other harmonics 2f, 3f etc. When we sample such a signal and use a program to calculate the Fourier transform, we obtain peaks of finite width. (If we sample a signal with vibrato we might see even broader peaks, but let's restrict this to a strictly periodic signal.) In fact, we could get very narrow peaks if we did one of two things.
First, we could use a very long signal and a very long sample window for the transform. This would give narrow peaks, going to zero width as the signal and window length approached infinity.
Second, we could use a window whose length was exactly an integral number of periods nT. (Of course, without having performed a Fourier transform on a very long sample we don't know exactly what T is...)
In practice, we rarely do either of these: even if the software used for the transform may offers a choice of sample length, its maximum value may not be long enough to produce very narrow peaks. In general, the width of the peaks is of the order of 1/t, where t is the length of the sample window – except in the case where the window has a length nT.
Why are so many physicists and mathematicians (and engineers and ...) good at music?
I am often asked this, and one can make a few observations about the similarities between the two. For instance, in physics or maths we start with a relatively small number of definitions and laws and with these, we attempt to explain almost everything in the universe. We build elaborate and detailed patterns in a heirarchy of structures, starting with quite simple elements. In music, we start with a relatively small number of pitches and durations. Again, we build elaborate and detailed patterns in a heirarchy of structures, starting with quite simple elements. The physicist and the musician recognise
these heirarchies and underlying structures, and find the elegance and beauty in them. I've elaborated on this and other ideas in a paper called The creation and analysis of information in music.
However, on a more pragmatic level, I think that it is helpful to look at it from the other direction. A good musician knows about practice: that an hour's solid work yields only modest advancement and that regular practice is necessary. S/he is capable of abstraction at several levels. S/he is capable of processing information rapidly and precisely.
So, take someone who is good at abstractions, capable of processing information rapidly and precisely and has the temperament to work in order to progress. Is it surprising that some musicians have aptitude for physics? All that one would need to add to this list, I suspect, is curiosity and wonder about the world. It's not surprising that many intelligent, creative people are good at physics, maths and engineering. It's also not surprising that they are good at music.
What makes the same note sound high or low on different instruments or different voices? For example, middle C (C4) sounds low when a flute plays it or a soprano sings it, but high when a tuba plays it or a bass sings it.
One important clue is the amplitude of high harmonics. When an instrument or singer performs near the top of the range, the fundamental is strong and the high harmonics are relatively weak. Towards the bottom of the range, there are usually many strong harmonics. For example, compare C4 on a flute (scroll down to the sound spectrum) with C7 on a flute. In the latter (high) note, the harmonics are about 30 decibels weaker than the fundamental. In the low note, the fundamental is relatively weak. (In turn, this is because instruments are usually in more strongly non-linear regimes at the bottom of their ranges.)
Why does a loud note still sound different from a soft note, even when you turn the volume down?
In many musical instruments, there is an oscillator (such as a reed, or the player's lips) that behaves in a non-linear way. For small vibrations, however, the behaviour is nearly linear. So louder playing means more non-linear behaviour, and more non-linearity means more higher harmonics. This is explained in more detail in, for example, how a reed works in a clarinet. There are sound files and spectrograms illustrating the effect in What is a sound spectrum?, whence this illustrtion:
Why does rubbing your finger around the rim of a wine glass make a note?
Like a percussion instrument, the glass will vibrate with a range of frequencies when you tap it (lightly). However, when you rub your finger around the rim, you are continuously putting in energy and so you produce a sustained note.
It works like this: over a time of a millisecond or so, the fingertip 'sticks' briefly to the glass, then 'slips' a little and, if the conditions are just right, the glass will vibrate so that the finger 'sticks' again, one period of vibration later. The mechanism is rather like that of the violin bow on the string: see Bows and strings.
Wine in the glass impedes the vibration of the part that it occupies, so you can tune the note by drinking some of the wine. Glasses of different sizes also have different pitches.
Some glasses ring for longer when you tap them: there is less internal loss of energy in the glass. These seem to be easier to play with the fingertip, too.
Benjamin Franklin invented an instrument called the 'glass armonica', consisting of a set of glass bowls, of varying sizes, on a spinning axle. The player touched a bowl to make a note. One of Mozart's last compositions (K617) was for glass armonica, flute, oboe, viola and cello.
What is aliasing and why does it produce ghostly harmonics?
For this question, we have made a separate page.
Questions related to string instruments
What is the difference between artificial and natural harmonics?
This contrast is made, to my knowledge, only by string players. Natural harmonics are played on an open string, as illustrated here, whereas 'artificial harmonics' are played ona a stopped string. The latter are of course more difficult to play, as you need one finger to stop the string and another to touch it at the desired node. See Strings, standing waves and harmonics and Standing waves.
How important are the materials from which string instruments are made?
For string instruments, in which vibrations of the material of the instrument is what radiates sound, the mechanical properties of the materials are of great importance. The stiffness, density, anisotropy and losses in the wood (or other material) are all important to the response and performance of the instrument. A complete answer would be very long. Briefly: the bridge is not quite stationary: it must move a little so that it takes a small quantity of the energy out of the string in each vibration cycle. This is used to vibrate the body and, particularly for low frequencies, a substantial area of the body must move in order to transmit energy effectively into the air. For a loud instrument and a good sustain of a plucked note, relatively little of this energy should be lost in the body. Further, the mechano-acoustical properties of the body should help make the sound interesting. The spectra of different notes should have overall shapes that are different (but not too different) so that the instrument has some character. For bowed string instruments especially, it is important that the body has properties that vary rapidly with frequency, so that a vibrato induces substantial changes in the spectrum. This is quite important to the characteristic warm sound of a bowed string vibrato. (See also How important are the materials from which wind instruments are made?)
What about electric guitars? In principle, one could imagine a tiny effect. First, the decay of standing waves in the strings depends on how much the bridge and nut or fret move. This is not much compared to acoustic instruments, but not zero, so the time for the note to decay could depend on the mechanics of the instrument. Second, the signal detected by the pickups depends on the relative motion of string and pickup, and in principle the pickups could move, though not very much. So my expectation is that any such effects are tiny, and at the level where detection would require sensitive apparatus. But I know of no study.
Why do you get odd tunings if you tune by harmonics?
If your instrument has four strings, tuned in fifths or fourths (violin family and bass) then it is likely that you will tune by harmonics, and you won't get very noticeably "odd" tunings. This question was asked by a guitarist.
Some background, and a method for tuning by harmonics, are given in Strings, standing waves and harmonics. But here is a specific guitar question. "I tune by first setting my E strings to a standard pitch, then using harmonics to match this string to adjacent strings. On the lowest E string, when one I hit the 4th fret harmonic to get G# (the third of E), it is slightly flattened. On the 7th fret harmonic to get B (the fifth), it is pretty much on an even division of E. When the chord is played after tuning this way, there are no beats, and this is what sounds in tune. Tuning the whole guitar this way yields some flat and some sharp strings, that all sound good together. I understand that this is the essence of temperement, well vs even or just. My question is, why is the 4th fret harmonic flat and the 5th and 7th frets on, and why does this eliminate beats? Is there a mathematical explanation that can be easily transmitted here?"
Your guitar fretboard is designed to produce pitches that approximate equal temperament - i.e. each of twelve semitones has the same frequency ratio (in that sense they are equal - our sense of pitch is close to logarithmic). An octave is 2:1 so that makes each semitone the twelfth root of two, 21/12, which is about 1.059. (Americans: semitone translates as halfstep.)
The ratio between the third and second harmonics of an exactly periodic sound is 3:2 which we call a perfect fifth in just intonation, or a pure fifth. (More on the "exactly" later, and see Sound spectrum for more explanation.)
The third harmonic, touched at the seventh fret: Seven equal-tempered semitones is 27/12 = 1.498, which is quite close to 3/2 (= 1.500). So an equal tempered fifth, plus an octave, almost equals the third harmonic, and so produces only very slow beats at ordinary pitches. Further, to play a fifth on the seventh fret, you've reduced your string length by about 1/3, so this is where you touch the string to get the third harmonic.
Your fourth fret observation: stopping the string here ought to give an equal tempered major third (four semitones). Touching the string here will give the fifth harmonic, which is two octaves and a major third above the fundamental. Four equal-tempered semitones is 24/12 = 21/3 = 1.260, which is not very close to a 5/4, which is a major third in just intonation. Here is the root of most of the problems which require temperament, which is described in another FAQ called temperament.
See also Tartini tones and temperament: a musician's introduction and the multimedia introduction at Tartini tones, consonance and temperament.
What is the "secret of Stradivarius"?
Why this question is difficult. Although much has been written on this, it is a subject that attracts a lot of speculation and relatively few facts.
The astonishing thing about Stradivarius is that many of the instruments attributed to him are judged to be excellent and comparable with the best modern instruments. Some would claim that Strads are the best, though this claim has only recently been tested (see below). To a small extent, some argue that such statements may be tautological: his instruments have so long been treated as the optimum, that is almost impossible to do better: an instrument sounding brighter than all (modified) Strads would be judged to be too bright; one sounding mellower would be judged too mellow. This doesn't seem to be the case, however: studies have shown that other violins can be judged, in blind comparisons, to be better than Strads.
To start, there are some complicating factors: One of the most obvious reasons why these instruments sound so good is that they are almost always played by superb violinists. It is also possible that some of the comment about the quality of Stradivarius' instruments may be complicated by the fact that the people who own or play them have a strong financial incentive to maintain their market price. Consequently, it is not often possible to perform blind comparisons, like the one mentioned below. Non-owners who have the chance to play one very rarely do so blind, and often have expectations that may colour their opinions and/or their assessments. So one must be cautious. However, on a FAQ in music acoustics, we cannot get away from this question, so here is my contribution.
How do they compare? Note that I wrote 'comparable' above and not (necessarily) 'better'. In one recent study conducted at the 8th International Violin Competition of Indianapolis, 2 famous Strads, one Guanari and three excellent modern violins were played and compared by 21 experienced players in double blind conditions. One of the modern violins was rated best, and one of the Strads last. (The lead author, Claudia Fritz, was once a PhD student in this lab.)
Strads are very good, but it's important to remember that they are not necessarily the very best violins.
Differences among Strads. Further, it is important to note that Stradivarius' violins are judged to differ subtantially in character from one to another, just as modern instruments do. This is in part because wood samples differ substantially in mechanical properites, even if taken from the same tree. Makers can compensate for these differences to some extent.
What did a Strad sound like? Important, because strads don't sound like the violins Stradivarius made. The word 'modified' in the paragraph above is important. Few, if any, of Stradivarius' instruments today sound anything like the instruments he made, so no-one knows what a violin made by Stradivarius sounds like. Over the intervening years, virtually all have been subjected to the following changes:
disassembly,
a bass bar has been fitted, the belly and bass bar retuned, and the sound post has been replaced with a thicker one,
the necks and fingerboards have been removed, discarded and replaced with longer, heavier necks and fingerboards at a greater angle to the body,
new, taller bridges, with different shapes and acoustical properties, have been fitted,
they have then been strung with more massive strings (steel instead of gut) at a much higher tension and tuned about a semitone higher,
quite a few of them have been repaired in ways that would be expected to make substantial changes to the sound.
To have an idea of the sound that Stradivarius would have heard from his instruments, go to a concert played by a group specialising in authentic performance. Some will play on old instruments, or more commonly on reproductions of old instruments, using gut strings and usually pitched about a semitone lower than the modern instrument. Many of them are in fact imitations of violins by Stradivarius. The contrast with the modern instruments is striking. So the difference between how a Stradivarius violin sounded as he made it, and how it sounds now is great. John McLennan did his PhD in this lab, studying these changes.
His thesis, related research and sound file comparisons of baroque, classical and romantic violins are on this link.
That said, the highly modified Stradivarius violins are still judged to sound very good, so is there a secret?
Is it in the varnish? Some people talk of secrets in the varnish. Some makers and players think that violins sound better 'in the white', i.e. before varnish is applied, than after. Varnish increases the mass of the plates slightly (which lowers resonant frequencies) and stiffens the plates slightly (which raises them) and can also increase mechanical losses (which makes the resonances weaker). So changes are possible. One of the techniques used with varnish (certainly not a secret) is to use only only enough to protect the wood, and not enough to make substantial changes in the sound. For those who like the romantic idea of the "secret of the Stradivarius", it's very attractive, however, to imagine some secret ingredient, and the varnish is a convenient place to imagine putting it.
Is it in the wood? Was the wood special, or did it become special due to environmental or artificial treatments. Again, for those who like the romantic idea of the "secret", this would be a convenient place to imagine putting it. We list some reported additives and treatments below.
So how did he do it? How is it that Stradivarius made a lot of consistently good quality instruments? Although some proposed 'secrets' are listed in the next section, it seems that nobody knows the whole story. So here are some observations and speculations of mine. First, he had good materials. Modern demand is high and modern makers compete for limited stocks of the best wood, especially sitka spruce. (The demand by the aviation industry for spruce in the first half of the twentieth century did not help: a lot of potential violins were turned into aeroplanes in the first world war.) Second, he had good training: he was an apprentice of Nicolo Amati, starting at about 13 years old. The third and most important point is this: he was a virtuoso maker. Take someone really gifted with all the right talents, give him superb training, provide him with a large supply of excellent materials, then put him in a town where good instruments are bought for good prices, in competition with other good makers. Result: Excellent instruments.
The various 'secrets of Stradivarius'. It seems that, whenever someone claims to have discovered the 'secret of Stradivarius', the media become excited about it. It has been suggested that we should maintain a list of these 'secrets of Stradivarius'. Here are a few, to which readers may wish to add by emailing us:
Stradivarius used the 'golden ratio' in the geometrical design. Anon., but widely mentioned.
"Experience. Stradivarius made his best violins between 1710 and 1720 at age 60 (died at age 93). His contemporaries didn't live to be 60 years old, so lacked experience." (Contributed by Jan Woning.) This hypotheis could be tested by comparing instruments made in his forties or earlier with instruments made in his sixties or later.
Shape and density. Sirr and Waddle, 2011. Measuring the shape and density of the wood using Xray scans could allow accurate replication of shape and density. But, given the variability in wood properties, would this produce the same acoustic properties? BBC report here.
Imperfections in the geometry. Tiny modifications including the geometry of the f-holes can be decteced by synchrotron radiation. Zanini 2012.
So, a range of theories. But it is worth reading this recent study by Claudia Fritz about the quality of violins.
How can you work out the appropriate size for a sound hole when designing an instrument?
Usually, the air resonance of a string instrument is set somewhere near the tuning of the second lowest string (a bit lower for guitars, a bit higher for bowed strings). I have included a discussion of the calculation on Helmholtz resonance, which gives a simple equation, and some warnings about the approximations used.
Can a resonating chamber (instrument body) amplify sounds? If so, where does the extra power (seemingly) come from?
Let's think first about amplification: a guitar amplifier takes a tiny electric signal from the guitar and, using electrical energy coming from the wall socket, amplifies it to produce a more powerful electric signal that goes to the loudspeaker.
Turn it off and there's no amplification, because there's no extra input of energy.
So no, the body of a violin or a guitar does not amplify.
Now let's compare a string on immoveable mountings (an unplugged electric guitar approaches this) with a string on an acoustic guitar. In the former, the bridge (almost) doesn't move, so no work is done by the string. The string itself is inefficient at moving air because it is thin and slips through the air easily, making almost no sound. So nearly all the energy of the pluck remains in the string, where it is gradually lost by internal friction.
In contrast, the string on the acoustic guitar moves the belly of the instrument slightly. Even though the motion is slight, the belly is large enough to move air substantially and make a sound. So the string converts some of its energy to sound in the air. Consequently, its vibration decreases more rapidly than does that of a similar string on an electric guitar. Internal losses in the string are still very important, however. (Technically, we could say that the body is an impedance transformer, matching the high impedance string to the low impedance air.)
So there is no extra energy: the energy for the sound comes from the string. Which raises an obvious question: if there is no amplification, how does such a little vibration make such a lot of sound? The answer is that our ears are rather sensitive (see our page on decibels and hearing). Consequently, even a small energy (even less than a millijoule) over several seconds makes a reasonably loud sound.
How much does one more violin add to the sound level of a section of n violins?
Let's make a few simplifying assumptions: that each violin radiates the same power P (not usually the case in amateur orchestras!), that the listener is equally distant from all of them (hard to arrange) and that there is no simple phase relationship among the sounds from the different violins (this one is safe).
Consider n violins, each with power P, that produce total power nP. Say that the intensity, at our listener's ear, due to one violin is I1. Thanks to our simplifying assumptions, the intensity due to n violins is then In = nI1. At this stage, you may need to look at our section on decibels, sound level and loudness. The sound level L1
(in decibels) for one violin, Ln for n violins and Ln+1 for n violins are all given by the definition
where I0 is an arbitrary, finite reference intensity (and is not the sound level due to zero violins!). Now to the question: the increase in sound level when you go from n to n+1 violins is
ΔL = 10 log(In+1/I0) − 10 log(In/I0)
Because of our simplifying assumptions, the intensity is proportional to the number of violins. The site on decibels etc shows you how to handle logs, and explains why log(a) - log(b) = log(a/b). This allows us to write:
Reaching for your calculator, you'll see that adding the second violin adds 3 dB to the sound level produced by the first, the third adds 2 dB to the level produced by the front desk, the fourth adds 1 dB, and so on, and adding the 15th violin gives you an extra 0.3 dB. The decibel page gives you sound file examples of how much changes of 3 dB, 1 dB and 0.3 dB in level sound like.
Of course, there is much more to it than that: multiple instruments give chorus effects that make the sound more complicated and give it a different quality. But if your orchestra has 15 firsts, the biggest difference will be your empty chair on stage.
Why does a thicker string sound less bright (have weaker high harmonics) than a thin string?
All else equal, a thick string doesn't bend as easily as a thin one: it is harder to produce a sharp corner in a thick string. So, when you pluck or bow a thin string, you create a shape that has sharper corners. When you look at the harmonics needed to make up this shape (see What is a sound spectrum? for background), you'll see that more and stronger higher harmonics are required to make a sharp corner. So bowing or plucking a 'hard to bend' or stiffer string puts in fewer high harmonics.
Further, a substantial fraction of the energy you put into a string is not converted into sound, but is lost in bending and unbending the string. So the stiffer string usually loses its high harmonics more quickly.
Finally, at the same pitch, a thicker string is usually shorter than a thin one: to play E4 on the top string of a guitar, you use the whole length. To play it on the B string, you need 3/4 or the length. To play it on the lowest string, you need only 1/4 or the length. So, all else equal, the high harmonics require sharper corners on the lower strings.
I've referred to stiffer or 'hard to bend' strings rather than just thick strings. It is possible to make a thick string (or, more importantly, one with a high mass per unit length) that bends relatively easily by using a thin core and winding wire around it to increase its mass per unit length (and therefore stiffness). The low strings on guitars, pianos and usually violins are wound strings. This allows them to have stronger higher harmonics, and also improves their harmonicity. However, if you make the core too thin, the string is easy to break.
For some basics about string vibrations, see Strings.
What causes sympathetic vibrations in a string? How is it different from the coupling between string and soundboard?
Sympathetic vibrations: You pluck the A string of a guitar, then damp it. You notice that the (high) E string is now vibrating, although you didn't touch it. Or you play an A on the G string of your violin, and the open A string starts to vibrate. What is going on?
When you pluck the low A, the vibration is not a simple sine wave with one frequency. Rather, it is a complex vibration whose spectrum has quite a lot of frequency components, most of which are nearly harmonic. So, as well as a fundamental at the pitch A2, it also has a second harmonic at A3, a third harmonic at E4 and so forth. So the string vibrates the bridge and soundboard of the guitar at all of these frequencies. Of course the top E string is tuned to E4, and the vibration of the bridge is exciting it at its own natural frequency, so it absorbs energy from the bridge. Then, when you damp the A string, no more energy comes into the E string, but the energy it has stored is now given back to the bridge and soundboard, as its sound fades away.
You can also excite sympathetic vibrations by singing a note whose fundamental or harmonic has the pitch of one of the open strings. Here the sound wave causes the soundboard to vibrate, which again stores energy in the string. If you open the lid of a piano, depress the sustain pedal, and sing a note (in tune), you will excite several sets of strings, and discover something about the spectrum of your voice.
How is it different from the coupling between string and soundboard? Sympathetic resonance usually refers to a phenomenon that occurs when two resonators (e.g. two strings) have very narrow resonances that are tuned sufficiently closely together (different in frequency less than bandwidth) so that energy stored in one is transferred to the other. The una corda pedal on the piano is a common example.
While the sound board has resonances, these are usually rather broad and aren't explicitly tuned to a note on the instrument. So, usually, the string drives the soundboard at frequencies of string resonance, which are not close to the resonances of the sound board, so relatively little energy is stored in the soundboard vibration. Instead, energy is continuously transferred from string to soundboard to rediation field, i.e. sound output. (An exception is the accidental tuning of the main belly resonance on the cello, which is rather narrow, near to a note on the D string: this is called a wolf note. The storage of considerable vibrational energy in the belly then rocks the bridge and disrupts the note, causing considerable annoyance to cellists.)
Why is it usually thought that a good violin should be hand made?
If you were to ask violinists, I expect that very many would admit that they wouldn't mind if some parts were machine made, such as the strings and the tuning pegs. And virtually all would probably state a preference for a violin that was hand finished: i.e. on whose back and belly plates had been finished by a specialist maker, and one whose final set-up, including soundpost height and position, had been carefully done by hand.
What about the belly and back? A computer controlled milling machine could, in principle, make these very precisely – perhaps copying exactly the dimensions of some agreed masterpiece. However, wood is a material with variable mechanical properties: two pieces of spruce with exactly the same dimensions will not necessarily vibrate the same way, because variations in grain and microstructure give rise to variations in mechanical properties. The skilled violin maker may therefore adjust the plate thickness to give desired properties (such as the low mode frequencies).
Rationally, one might also argue that a computer controlled milling machine could make a scroll and neck more quickly, cheaply and even perhaps more neatly than a human maker. Such machines are more commonly found in a factory than in a small workshop.
So one might expect that some parts of manufacture are most efficiently done in a factory and that others are best done by a very experienced maker. The varying proportions of each would cover a big spectrum, from a factory with a production line and hand finishing, to a collective of makers who share expensive machinery for some operations, or a maker who subcontracts the building of some components. (I declare an interest: my viola and bass were made by companies that use a combination of mass production and hand making, and I am very satisfied with these instruments, whose quality easily surpasses my ability.)
However, there is more to the story than this. First, mass producing some components makes a big difference to the price of cheap instruments, a useful difference to mid-range instruments, and very little to high priced instruments. If you are paying a maker's wages for a month or two to make you an instrument, you might well think about paying for an extra day to carve some components that s/he could buy ready made. Second, there is the tradition: it is still possible for one person to make (nearly all of) a violin in a simple workshop, and keeping this tradition alive is appealing in an age in which, for example, cars and computers are no longer thus made. (The photo shows the celebrated maker of more than 500 instruments Harry Vatiliotis.) Third, and perhaps most importantly, there is the relationship among the maker, the violinist and the instrument. This develops over the month or two that it takes to build the instrument, and often involves several visits. Particularly once it is strung, the player has the chance to influence the properties of the instrument.
Questions related to wind instruments
How do you explain the waves and harmonics in flutes, clarinets and oboes? A flute is open at both ends and a flute ~60 cm long plays a lowest note of C4, which has a wavelength about twice as long as the instrument. A clarinet is open at one end and closed at the other, so it should play a note about four times as long as the instrument, and it does: a clarinet is ~60 cm long and playes a lowest not of D3 or Db3, nearly an octave below the flute. So far so good. But an oboe is also ~60 cm and closed at one end, and its lowest note is much closer to the lowest note on a flute than to the lowest note on a clarinet. Why?
This question requires diagrams and a bit of concentration. I've devoted a whole web page to it at Pipes and harmonics.
Why does a sound wave reflect at the open end of a pipe?
Let us imagine a pulse of high pressure and therefore high density air travelling down the tube. When it reaches the end of the tube, its momentum carries it out into the open air, where it spreads out in all directions. Now, because it spreads out in all directions its pressure falls very quickly to nearly atmospheric pressure (the air outside is at atmospheric pressure). However, it still has the momentum to travel away from the end of the pipe. Consequently, it creates a little suction: the air following behind it in the tube is sucked out (a little like the air that is sucked behind a speeding truck).
Now a suction at the end of the tube draws air from further up the tube, and that draws air from further up the tube and so on. So the result is that a pulse of high pressure air travelling down the tube becomes a pulse of low pressure air travelling up the tube. We say that the pressure wave has been reflected at the open end, with a change in phase of 180�.
Compare this with what happens when a pulse of high density, high pressure air arrives at a closed end. It collides with the blockage at the end. It could be considered to 'bounce off' it: the high pressure on the blockage pushes air back in the way it came. Here we say that the pressure wave has been reflected at the closed end, with a change in phase of 0�.
Incidentally, a physicist would explain both of these in terms of the acoustic impedance. The acoustic impedance has an infinite value for the closed pipe, a very low value outside the pipe, and an intermediate value inside the pipe. The acoustic impedance is (in a limited sense) analagous to the refractive index for light: going from low to high acoustic impedance, there is reflection of the pressure wave with a phase change of 0�. Going from high to low, there is reflection with a phase change of 180�.
First, look at the animation in the section above about reflections at an open end of a pipe. When a pulse of high pressure air gets to the end of the pipe, it spreads out, and that allows the reflection. What happens exactly at the end? inside the tube there is a plane wave, when the wave is radiating externally it is a spherical wave, but between the two there is some complicated geometry. In this phase, the pulse of air is not in the free, unimpeded air away from the pipe, nor in the tightly constrained environment of the pipe. It is somewhere between the two: unconstrained on one side, but constrained by the pipe on the other.
As we explain above, the reflection is caused by suction that results when the momentum of the pulse of air takes it away from the pipe. But this suction doesn't appear immediately when the pulse reaches the end of the pipe, but a little later, as it starts to spread out.
So the reflection appears to occur slightly beyond the open end of the pipe. To a rather good approximation, this effect can be calculated by saying that the effective length of the pipe is a bit longer than its geometrical length. The difference is called the end correction.
For a closed end, there is no such end correction. For a simple cylindrical pipe as shown above, the end effect at the open end is 0.6 times the radius. Note the consequence of this: all else equal, a large diameter organ pipe is a little flatter than a thin one.
If you look closely at the animations above, you'll see that we have included end effects. Although the geometrical lengths of the two pipes are equal, the open-open pipe has two end effects and so its effective length is slightly greater than that of the open-closed pipe. Hence the travelling pulses get successively further out of step with each lap of the pipes.
Do end corrections, such as those produced by varying the key clearance above a tone hole, have the same effect on different registers?
I'm warning in advance that this question is a bit subtle, and so I'll have to refer you to some technical discussion, but shall try to answer it here.
If the frequency were well below the cutoff frequency, then the end effect would be primarily due to the mass of the air in the open tone hole. (See a brief explanation of cutoff frequency.) So the acoustic impedance would be very small and it would be almost completely an inertance, therefore we could model it as a small extra length, and this would not narrow octaves.
However, on real geometry instruments, the second register is rarely well below the cutoff frequency. That's why cross fingerings produce semitones
on small hole instruments, even in the first register, and why they flatten
notes in the second register of larger hole instruments. (We have a paper on cutoff frequencies and cross fingering on our 'publications' site where you can
get explicit values and examples.)
So, if you are serious about tuning, you can rarely neglect the wave that
is transmitted past the first or second open hole. At low frequencies, this
impedance (in parallel with the open hole) is usually inertive. But as you
get close to the cutoff, it can have either sign. So it is possible for a cross
fingering to sharpen a note, particularly in the second register of a small hole instrument like
recorder or shakuhachi.
To imagine this without doing calculations, it is sometimes possible to
think of the cross fingered note as being in a high register, with the open hole
under discussion functioning as a register hole. However, near cut off, the
situation becomes rather complicated and such qualitative arguments cannot be
trusted.
Of course, musicians naturally prefer such 'arm-waving' explanations, even
if they are not very reliable. So, on our databases for flute, clarinet and saxophone, I tried to give a qualitative explanation, except for the very highest
notes. (Now that will be a challenge when we get to the bassoon!)
How far is 'well below cutoff'? That depends on the precision required. Remember
too that cutoff varies somewhat from note to note.
How important is the air speed in playing musical wind instruments? And how does it relate to pressure? (Teachers do talk about it a lot.)
First let's distinguish two quantities that are often confused. Like other speeds, air speed is measured in metres per second.
Air flow (or air flow rate) is measured in cubic metres per second or, more practically, in litres per second. In playing a musical instrument, the air flow through your mouth is typically in the range 0.1 to 1 litre per second*. The air speed times the cross section through which it flows gives the flow rate: if a wind of 1 m/s flows through a window with area 1 square metre, then one cubic metre of air enters the window per second. Let's do some instrument examples:
Take a the typical wind player's flow range of 0.1 to 1 litre per second, divide by 10 square centimetres (a typical cross section in a broad section of the mouth or throat) and the air speed at that point in the mouth is 0.1 to 1 metre per second.
Divide the same flow by 1 square centimetre (the cross section of a small instrument bore, or above the tongue if you hold it near the hard palate). Here, the air speed is 1 to 10 metres per second. This is the average+ air speed in the bore of that instrument at that point. (If it were 1 m/s at the entrance to a saxophone, it would decrease steadily down the bore as the cross section increased.)
Divide it by 0.1 square centimetres (a small but possible average gap between a brass player's or flautist's lips, or a reed-mouthpiece gap) and the speed is 10 to 100 metres per second. A speed of 100 metres per second requires a mouth pressure of about 6 kPa, which is a moderately large but possible blowing pressure. Thus a player could simultaneously have an air speed of 1 m/s in the back of the mouth and 100 m/s between the lips.
The speed of air between the lips can be important functionally. For the flute, the time that the air jet takes to travel from the lips to the sharp edge of the mouthpiece is important to the register (fast jet for high pitch). For brass instruments, fast moving air between the lips exerts a suction that helps close the lips in their vibration.
For reed instruments, the fast moving air between reeds or between mouthpiece and reed can also contribute to closing that aperture (see the pages on flute acoustics, clarinet acoustics, saxophone acoustics and brass acoustics for details).
The speed of the air entering the instrument (or leaving the lips in the case of the flute) is approximately proportional to the square root of the blowing pressure** in the mouth. So blowing pressure determines the air speed into the instrument, and air speed times the cross section(between lips or reeds gives the flow. So, if you keep that aperture constant and the blowing pressure constant, then the air speed in your mouth depends on the cross section of the mouth and vocal tract. So the speed might be fast at a point where the tongue constricts the tract, but slower elsewhere – and usually much slower than the rate at which it enters the instrument. It might also be fast at the larynx, if you play with your vocal folds adducted. Scientists who study wind instruments are much more interested in the blowing pressure and the air speed between the lips or reeds than we are in the varying air speeds in the mouth.
Speed means pretty much the same thing to scientists as it does in common use. But it's possible that teachers don't mean the same thing when they say 'maintain air speed'. So what�s it about? They may be using the phrase metaphorically. Or perhaps a teacher's exhortation to maintain air speed in the mouth is an implicit instruction not to vary the blowing pressure too much (useful because the pitch depends on blowing pressure, all else equal). Or it may be an indirect way of promoting a vocal tract shape that has particular acoustic properties. For example, clarinettists and saxophonists tune their vocal tract resonances for altissimo playing and exotic effects. However, when playing the clarino register, clarinettists also adjust the resonant frequency of the tract even when though they are not tuning it to the note played. Or perhaps the discussion of air speed tends to achieve some other effect, in which case I�m interested to hear suggestions about what it might be.
(I made a page for this topic.)
* You can estimate your rate of air flow. Take a big breath of air and exhale all of it and you have probably exhaled about five litres. If you do that in five seconds (a loud note on say trombone or saxophone) then your flow rate is one litre per second. If you exhale it over 50 seconds (a long note on oboe) then your flow rate is one tenth of a litre per second. If you also know the aperture (a flutist can look in the mirror to see the gap between the lips) you can estimate the air speed.
+ This discussion concerns average or DC flow. Inside the instrument, the acoustic or AC flow becomes important: it can have a magnitude larger than the average flow, so that the air at the bell is oscillating in and out of the instrument much faster than it is (on average) flowing through it.
** This result, sometimes known as the Bernoulli effect, comes from Newton's second law via the work-energy theorem: the gain in kinetic energy of the air in this narrow passage equals the work done by the air pressure in the mouth. This kinetic energy is then nearly all lost downstream in turbulence.
Warming up wind instruments. As a saxophone warms up, you need to pull the mouthpiece out to keep it in tune. Thing is, this doesn't seem right to me. As a sax gets warmer, I should think it would expand, making the tube bigger and longer, forcing a player to compensate by pushing the mouthpiece in to shorten it up.
Metals expand by about .001% to .002% per �C. And in any case, the metal itself doesn't warm up much. So the expansion of the metal is not significant when the instrument warms up. Some important effects do occur, however.
First, the air inside becomes warmer. The speed of sound in air is proportional to the square root of the absolute temperature. Normal temperatures are roughly 300 K, so it takes about 6�C to change the speed of sound by 1% (K is for kelvin, the units for absolute temperature. A temp difference of 1�C equals a temperature difference of 1 K. Add 273 K to the temp in �C to convert.)
Another important thing is that the air in the instrument becomes humid: your breath is nearly saturated at 37�C and when it cools in the instrument, water condenses on the metal providing a water reservoir to keep the air nearly saturated in the instrument. Further, saturated warm air has a higher concentration of water vapour than cold air. The speed of sound is inversely proportional to the square root of the average molecular mass of the air. Water molecules are lighter than nitrogen or oxygen, so humid air is less dense than dry air, all else equal. (Yes, I know that non-scientists talk about humid air being 'heavy', but I think that by this they mean that one sweats less effectively in humid air.)
These two effects add up, so it's easy to have 1% or even 2% or more increase in speed of sound, and therefore in playing frequency. A semitone is only 6%, so this is a lot.
Countering this, happily, is the effect of CO2.
This is denser than ordinary air and, especially if it's been a while since you last breathed in, the expired air has increasing concentration of CO2, which lowers the pitch. In some circumstances, this effect can be bigger than those of heating and humidity, especially in big brass instruments (e.g. tuba) that require a lot of air and that don't heat up much.
We have a lay-language page explaining this further. (We studied these competing effects for the trombone in this paper. One conclusion: a 1% increase in frequency requires either a 6�C increase in temperature, a 3% increase in water concentration or a 6% fall in CO2 concentration, or some linear combination of these. (Concentrations are measured as a fraction of all gases present.) Another interesting observation is the decrease in the quality factor of the instrument resonances with increasing humidity.)
How important are the materials from which instruments are made?
It varies among different instrument families. The type and quality of wood used in string instruments is very important, because the vibrating wood provides the sound of string instruments. In wind instruments, the materials are of much less importance, provided that they are sufficiently rigid. The walls do vibrate – one can sometimes feel the vibration for some notes. In common brass and woodwind instruments, however, the walls radiate at most an extremely small fraction of the total sound, so any wall vibration contributes directly at most a tiny component of the sound. One can imagine that the slight vibration during playing could affect the motion of the air jet, reed or lips driving the pipe, but this would be a very small effect. The vibration of the instrument itself is also part of the feedback that the musician receives, and so may be important for psychological reasons. The vibration of the bells of trumpets and horns is measurable and this might have a small effect, probably indirect, on the
sound. Again, a feedback on the lip of the player is a possible mechanism.
The appearance on the market of plastic trombones raises the obvious question: do they sound as brassy as trombones made of brass? The simple answer is that they sound very similar to trombones made of brass. Acoustic differences between two different trombones from two different manufacturers (in whatever materials) can usually be measured but these differences are likely to have more to do with small differences in geometry than with differences in materials.
In wind instruments, especially woodwinds, the material usually influences the shape, often in subtle ways. For example, different woods give different surface roughness when the bore is made with the same mandrel or reamer. This is complicated by the effects of humidity and oiling on different textures. Rough surfaces can make a difference not only to the timbre but to the pitch, as well.
Different metals adopt different shapes when they are formed on the same mandrel. Different materials may be easier or harder to shape, and so the sharpness of corners may be different at, for example, the junction of a tone hole with the bore, or the edge of the embouchure hole
in a flute. Further, different materials have different prices. If an instrument is to be made from very expensive materials, it is likely that the most talented or experienced maker in the factory will be asked to make the instrument. All of these effects may produce differences in the detailed shape of the instrument, and some of these differences are likely to be at least as important as the effect of any vibrations transmitted to the walls.
For metal flutes, a comparison experiment was done by Widholm and colleagues at the Universitat fur Musik in Vienna. For their study, they used seven flutes made by Muramatsu that were solid silver, 9 karat gold, 14 karat gold, 24 karat gold, solid platinum, platinum plated and silver plated. (Although they were the same model, these flutes may not have been identical in shape, for the reasons mentioned above.) Seven flutists (from the Vienna Philharmonic and the Vienna Opera Orchestra) played them, and were among the 15 experienced professional players that formed the listening panel. Two different sets of blind listening tests were conducted. In one, no instrument was correctly identified, in the second, only the solid silver instrument was identified by a significant fraction of the listeners. There was nearly complete confusion* over the quality and identity of the instruments. The authors conclude that the wall material does not appreciably affect the sound color or dynamic range of the instrument. (See also How important are the materials from which string instruments are made?)
* Of couse, everyone wants to know: even if the differences were small, which one did best? Ranked on a scale of 1 to 5, the solid silver did 'best' and the 9 carat gold did 'worst' . However, if one rates the instruments by subtracting the number of 'don't like it' from the number of 'like it', the 9 carat gold did best and the solid silver did worst. This apparently paradoxical result is due to the statistical variations in very similar rankings.
Widholm, G., Linortner, R., Kausel, W. and Bertsch, M. (2001) "Silver, gold, platinum--and the sound of theflute" Proc. International Symposium on Musical Acoustics, Perugia. D.Bonsi, D.Gonzalez, D.Stanzial, eds, pp 277-280.
In principle, one could imagine that the acoustic waves in the bore could couple to mechanical modes in the walls of the instrument. However, nearly all wind instruments have circular cross sections (exceptions include square cross-section organ pipes) and this makes such coupling very much weaker, because small changes in the eccentricity of an ellipse have least effect on the area when the ellipse is a circle. Further, instruments are made of materials rigid enough to withstanding handling, they have chimneys and other structures tend to stiffen them and the player's hands tend to damp wall vibrations. Finally, the relevant wall modes occur at frequencies well above those which have substantial acoustic pressure variation. Nevertheless, such coupling can be measured – if you can avoid all the above conditions. Neuf et al.* made an artifical 'instrument' with an elliptical cross section, out of metal much thinner than that used for wind instruments, with low frequency breathing modes, with no chimneys or other stiffening, and with no hand damping. In this very extreme example, they were able to measure coupling between wall vibrations and the acoustic waves at the frequencies of some of the resonant breathing modes of the walls. They conclude, of course, that there would be no such effect on musical instruments, with the possible exception of some organ pipes.
* Neuf, G, Gautier, F, Dalmont, J-P and Gilbert, J (2008) "Influence of wall vibrations on the behavior of a simplified wind instrument" J. Acoust. Soc. America, 124, 1320. The choice of elliptical cross-section was made because, for such a tube, wall vibrations have a first order effect on cross section, but no such effect on a circular cross section.
There is a subtle difference for brass instruments, because they have a bell, which is not cylindrical and not so rigid as the rest of the instrument. The vibrations of the bell can change the reflection of the wave in the bore, which would be expected to have some change on the sound and also perhaps on the sensation for the player. One experiment measured the input impedance and transfer function of a trumpet in two such conditions. Would you hear these differences? Some researchers think so.
Kausel, W., Zietlow, D.W. and Moore, T.R. (2010) "Influence of wall vibrations on the sound of brass wind
instruments" J. Acoust. Soc. America, 128, 3161.
This topic will probably be discussed for a long time. Some musicians clearly prefer one instrument (made of material X) to another (made of material Y). The musicians are sensitive judges. The question that scientists will ask is whether the differences are due to some acoustical effect of the materials (which seems unlikely in woodwinds), due to a different shape that is the result of using a different material (which is plausible) or due to some more subtle, indirect effect.
Can you make a flute mute? Is there a way I can practise in the middle of the night without disturbing the whole house and at the same time learning how to play notes and music?
Two ways. Put a small piece of cotton wool in the headjoint. This works well on the low range, but less well at the high pitches where you will wake the neighbours. Alternatively, put a piece of modelling clay on the edge of the embouchure hole, just opposite where you blow.
How do clarinet players do that big glissando in Rhapsody in Blue?
Several effects are used by the player to achieve this spectacular, smooth ascent in pitch. First, the clarinet has seven holes that are covered by the fingers, rather than keys. By gradually sliding the finger off the hole, one can obtain a smooth transition from one note to the next. This is how the first part of the glissando is achieved. The player can also change the position and force of the lower lip on the reed, thereby changing its natural frequency.
Most importantly, however, s/he also uses the resonances in the vocal tract. Normally, the resonances of the instrument are so strong (have such high acoustic impedance) compared with those of the vocal tract that the latter make only modest changes to the pitch. However, in the upper range of the instrument the player can produce resonances of the vocal tract that can be comparable in strength with those of the instrument, so the note played tends to follow that of the tract resonances, which the player increases smoothly--with some considerable help from the sliding fingers and the change in the natural frequency of the reed as the player's bite changes simultaneously. This is explained in detail in a recent scientific paper.
Why is a trumpet called a Bb instrument and an alto sax an Eb instrument? I saw your website and I was wondering how you would simply explain to a beginning clarinet or trumpet player why they have transposing instruments.
In the time of Bach and Mozart, trumpets and horns had no valves. Instead, the players played notes in the harmonic series, and lipped them into tune. See Harmonics of the natural trumpet and horn on our brass acoustics site. If the piece was in C major, and you had a horn of the right length, you could play C3, G3, C4, E4, G4, A*4, C5, D5, E5, F*5, G5 A5 etc, where "*" means half sharp--the notes you had to lip up or down. You then had a "horn in C". If the piece of music were in Bb instead of C, then you could remove a piece of pipe (called a crook) from the instrument, replace it with a longer one, to give you a "horn in Bb". The series then becomes Bb2, F3, Bb3, D4 etc. So your lowest (normal) note is a Bb, rather than a C, the note above that is F instead of G. And there was a different series to learn for each key. To make it easy for players, the music for the horn was transposed to the key of C and the player was told to insert the appropriate crook. (If the score is in Bb, then the "Bb horn" player's part would be written with no flats, and each note raised a tone.) This tradition continued for horns long after the invention of valves.
Modern brass instruments have valves (or slides) and can play all notes with relative ease. However, the tradition has remained to call C the lowest note played with no valves depressed or the slide completely in. For most trumpets, this is Bb (though trumpets are also made in C, D, A and Eb) and for most horns it is F and Bb. An advantage is that, once you have learned the fingering for the trumpet (in Bb), you also know the fingering for the horn in F (at least if you don't use the thumb valve), the euphonium in Eb etc. Or at least this works in military bands. For orchestras, you had better learn to transpose.
A similar situation occurs in woodwinds. The alto flute is mechanically similar to the normal flute, but is 33% longer. So the same fingering plays notes with frequencies a fourth lower in pitch. For that reason, it is called an alto flute in G, and the music is written a fourth higher than it sounds: the flutist can swap without having to learn new fingerings. Similarly, the cor anglais (in F) sounds a fifth lower than the oboe for the same fingering. (In the few nervous moments between the first and second movements of Dvorak's New World Symphony, the player who has put down an oboe and picked up a cor anglais doesn't have to think about new fingerings.)
Clarinets and saxophones come in a large range of sizes, and many of them are in Eb or Bb. You can go from alto to tenor saxophone without learning new fingerings. However, most clarinettists in orchestras will carry a case with two clarinets that share the same mouthpiece: one in Bb and one in A. So why have two instruments only a semitone apart? This is a vestige of the days when clarinets had few keys and it was (more) difficult to play in keys with several sharps or flats. So if the piece had flats, the clarinet part was written for Bb clarinet (two fewer flats), if it had sharps, the clarinet part was written for A clarinet (three fewer sharps).
Of course, one could manage without transposing instruments. Recorder parts are not transposed, and the player learns that all holes closed is F on an alto recorder and C on a tenor. Further, while an orchestral tenor trombonist calls first position Bb and reads bass clef, a brass band trombonist may learn that first position is C and reads treble clef, displaced by an octave.
In hindsight, it is a messy result. However, the complications of overcoming it are considerable, so we are likely to retain it for a long time. And yes, you'd better learn how to transpose at some stage.
How can I change a C trumpet to a Bb trumpet and vice versa?
Some trumpets have two tuning slides: the normal U shaped piece with the water key and two straight pieces, spaced with rods, that fit between the U slide and the trumpet. Sometimes, when the two straight pipes are in place, the trumpet plays Bb with no keys depressed. Take it out and it plays C. (In other cases, it converts a high pitch Bb trumpet to a low pitch Bb trumpet, in others an A trumpet to a Bb trumpet. You'll find out easily!)
Caution: The second valve should increase the effective length of the trumpet by 6%, the first by more than 12%, the third by 19%. But 6% of the length is different depending on whether or not the extra slide is in. So, to convert from C to Bb, you not only need to add the extra slide, but also to increase the length of all your valve slides, which may mean new slides.
What are multiphonics? How can you play two
notes at a time on a woodwind instrument?
Let's use the flute as an example, but the principle is similar for all woodwinds. In a 'normal' note played on a woodwind instrument, especially in the low range, all (or nearly all) of the tone holes downstream of a certain point are open, and all those upstream from that point are closed. The pipe behaves approximately like a pipe that stops near the first open hole. (For more detail, see tone holes on our introduction
to flute acoustics.) Multiphonics are usually produced by opening a single tonehole, usually a small one, somewhere in the line of closed tone holes, but not at 1/2 or 1/3 of the way along the pipe. (At these positions, the hole would function as a register hole.) A wave travelling down the closed-hole part of the pipe can be partially reflected at the first open hole. And part of the wave can travel down to the first open hole in the series of open holes, where it is reflected. This gives rise to two standing waves, with different wavelength, and therefore different pitch. Figure 1 in our downloadable paper The virtual Boehm flute--a web service that predicts multiphonics, microtones and alternative fingerings" shows this diagrammatically and gives further explanation. Technically, we could also refer to the acoustic impedance spectrum or "frequency response" of the instrument for a given fingering. Two non-harmonic minima in this function can give rise to multiphonics. You can inspect many such spectra for multiphonics with the virtual flute. There is a further discussion of multiphonics
on the topic what is an undertone?
What happens when you sing or whistle into a musical instrument?
It is usually possible to sing while playing a wind instrument, and this causes one type of multiphonic, where your voice (your vibrating vocal folds) makes one note and the instrument the other. Normally, the pitch of your voice is determined by the pressure in your lungs and the tension and geometry of your vocal folds. (So your voice is not like a musical instrument: the resonances of the vocal tract, which have rather high frequencies, rarely control the vibration of your vocal folds, which have much lower frequency.) This raises the interesting question: why does the instrument control the frequency of vibration of your vocal folds the way it controls the vibration of the reed or your lips, depending on which instrument you are playing? The answer is that, if the frequencies are comparable, it can happen.
The complete answer is a bit subtle and involves impedance matching.
(When you whistle normally, one of the resonances in your vocal tract
controls the frequency of vibration of the air jet and thus determines the pitch. If you seal a musical instrument around the outside of your lips you'll now have two resonators joined to it and rather more complicated conditions. When I tried that, I couldn't whistle.)
What is an undertone in flute playing and what causes it?
Sometimes when a flutist plays a high note, one hears a faint note at a lower pitch. Normally there is no exact harmonic relation between the two. This is what I call an undertone. (This is not to be confused with Tartini tones or other combination tones, in which two notes, often from different instruments, interact.)
The undertone is a special case of a multiphonic, usually produced accidentally. Let's take a simple example. Play the note D6, but play it with a relatively large opening between the lips. Then, still with large lip opening, reduce the air speed gradually. When the jet is slow enough, the note will drop down to C5 with a rather breathy tone. However, on the way you will pass through the multiphonic C5&D6. By adjusting the jet speed, you can vary the proportions of the two notes: when they are about equally loud, you have a standard multiphonic. (If you have never played multiphonics before, this is an easy one with which to start, although it's not very interesting. See multiphonic fingerings for more.)
Let's now see why this works by consulting the database on flute acoustics. The fingering for D6 is a bit like that for G4, except that you raise your left index finger and open one of the small holes on the flute. The harmonics of G4 are G4, G5, D6 etc, and all can be played on the G4 fingering. When you open the index finger key, you create a register hole that both weakens substantially and mistunes the second resonance, the one that supports G5, so that G5 becomes unplayable. This is the object of a register hole: you don't want your D6 dropping down to G5 when you decrescendo. The lowest resonance is also very much changed: it is weakened a little, and its frequency is
raised. You can think of this lowest resonance as a cross
fingering for C5.
To understand this, open a new
window for G4 and another for D6. The impedance curves tell us (approximately) which notes the flute can play for any fingering. The flute will usually play a note where it has a (sufficiently strong) resonance, and the resonances are the deep minima in the curves of impedance. The first three of these for G4 are at about 400, 800 and 1,200 Hz, and they play G4, G5 and G6. They also support the first three harmonics of G4, so these frequency components are consequently strong in the sound spectrum of the note played. The first three minima for D6 show a reasonably strong minimum for C5 (near 520 Hz), a shallow (unplayable) minima above that (near 900 Hz), then the strong minimum for D6 at 1.2 kHz. There are no minima to support harmonics of C5, which is why this (and other crossfingered notes) sounds darker and weaker than a normal fingering. (In fact, thi is the normal fingering for C5
on a baroque flute and explains why that note is darker than its neighbours.) If you found this paragraph heavy going but are still keen to understand it all, you might want to read our Introduction to flute acoustics. If you would like to see this particular multiphonic discussed in technical detail, download this this paper.
In the sound spectrum for D6, you will see the fundamental of D6 (near 1.2 kHz), which corresponds with its resonance in the impedance graph, but no trace of undertone: the impedance curve shows a resonance near 520 Hz (C5) but there is no signal in the sound spectrum at this frequency. No surprise: the recording is of a professional flutist. However, you can now see how a beginning flutist, with a wide lip opening and not much breath control, might play D6 with an undertone: s/he is playing a multiphonic with a weak lower note.
In the fourth octave, it is much easier to produce an undertone, because the required jet speed is very high, and so it's easy to blow too slowly! For instance, if you look at the sound file for the note F7 (open a new window for F7), there are a few things to observe. First, there is more breath sound because the required jet speed is much higher. Second, the resonances are much weaker (this is because there is more 'friction' loss between the air and the flute tube at high frequency). You will also observe in the sound spectrum that, as well as the strong harmonics at F7 and its harmonic F8 (about 2.8 and 5.6 kHz), there is a component a little above 2 kHz (near C7). Personally, I cannot hear this pitch but, if I could, that would be an undertone. When less accomplished flutists play F7 with this fingering, they are more likely to produce noticeable undertones.
Finally, we should note that Geoff recorded these sound files before we had built the virtual flute (TVF). If we asked him to record F7 today, he would use one of the fingerings that TVF recommends, some of which are substantially easier to play and so yield less breath sound and less chance of an undertone.
What is an end correction for a wind instrument? Can you explain it in layman's terms? And what causes it?
The simplest calculations that we can do to calculate the frequency that a wind instrument plays turn out to be only approximately correct, for reasons we explain below. The 'effective length' is the value of length that, when substituted into these approximate equations, gives the correct (ie measured) frequency. The difference between the 'effective length' and the real length (the one you measure with a ruler) is called the end correction.
For example, suppose that I take a piece of pipe, 170 mm long, sealed at one end, and I excite a resonance. I could do this by playing a pure tone nearby, then varying its frequency until I found the value at which the pipe would resonate -- ie start to produce its own strong vibration. ( I could also excite it by blowing over the end, as one does with a quena or shakuhachi, but then my face would change the end effect. Indeed, this is one of the important performance details of shakuhachi playing: by changing the angle with the face I can change both the end effect and the jet length, and get spectacular changes in pitch. See shakuhachi for details. There is a similar but less variable effect for the flute, discussed below.)
Now to the calculation of frequency. Suppose that the temperature and humidity are such that the speed of sound is 340 ;m/s (to make the numbers convenient). Because the pipe is closed at one end like a clarinet, I look up Clarinet Acoustics and see that the lowest resonance should have a wavelength about 4 times longer than the closed pipe. (If the pipe had been open, I should have looked up Flute Acoustics and seen that the wavelength is twice the length of the open pipe). Now 4 times 170 ;mm is a wavelength of 0.68 ;m , and so the frequency, which is speed of sound divided by wavelength, should be approximately 340/0.68 ;Hz = 500 ;Hz. (Similarly, a pipe open at both ends has a wave of 2 times 170 ;mm is a wavelength of 0.34 ;m and so a frequency of approximately 1000 ;Hz.)
I now take the pipes, excite them acoustically, and the resulting sounds have frequencies of approximately500 ;Hz and 1000 ;Hz for the closed and open pipes respectively. But not exactly. In fact, the measured frequency is slightly lower than what I calculate, and the bigger the diameter of the pipe, the bigger the depression of the pitch. The pipe could be said to behave as though it were a little longer than it really is. (In other words, the 1/4 wavelength (1/2 wavelength for open pipes) of the simplest diagrams is slightly longer than the pipe.) Now the effective length is the length that would give me exactly the measured frequency. Thus, as we said above, the effective length minus the real length is called the end correction. (For the open pipe, there will be two end corrections, one for each open end.)
What causes the end correction was first analysed quanitatively, for the simplest case, by John Strutt (a.k.a. Lord Rayleigh). When the air in a pipe vibrates in a resonance, it does so along the axis, with maximum vibration at an open end. Just outside the open end is some air that must be pushed forward and backwards by the vibration of air inside the pipe. That air has mass and inertia, and its that inertia that lowers the pitch. Outside the pipe, the sound wave radiates in nearly all directions, so the further you go from the open end, the less the effect. So only air very near to the pipe is involved. We can imagine this extra air as making the pipe effectively longer than it really is. So how much longer? For a simple open pipe, the extra length is about 0.6 times its radius.
End corrections are more complicated in real instruments. The end correction at the foot of a flute for the lowest note of the instrument is indeed about 0.6 times its radius. It's different if there is a bell. For example, see this link for the effect of a clarinet bell. It's also complicated at the other end. For a clarinet, the pipe is not completely closed, and the end effect depends on the properties of the reed. For the flute, the pipe is open at both ends, but you can vary how open it is by rolling the embouchure hole towards you (which makes a longer end effect -- the note goes flat) or away (conversely). There is also the small volume between embouchure hole and the cork -- see lipping up and down on our page introduction to flute acoustics for further explanation. For brass instruments, the mouthpiece, the mouthpipe, the flare and the bell complicate things even more: see effects of bell and mouthpiece on our introduction to brass acoustics.
Finally, if we consider a woodwind instrument with several open tone holes, it is not just the air outside the first tone hole that must be vibrated, but air inside the bore, too. So the end correction is longer here. It is also longer to explain, and it becomes longer and more complicated still when there are cross fingerings. If you want to see how this works, download our scientific paper, in which we measure how far waves of different frequencies propagate past the first open hole, both for simple and cross fingerings.
What is the difference between whistle tones and edge tones on a flute?
I was about to try to answer this when I rememberd Benoit Fabre who, as as part of presentation to a scientific conference on music acoustics, gave a brilliant performance on the flute, using whistle tones. Here is his response:
There is considerable confusion between WhistleTone (WT) and Edge Tone (ET), probably because both are played very softly. Two arguments showing that WT are not ET. 1. The frequency of oscillation of a WT is always fixed at a passive resonance of the pipe and jumps from resonance to resonance as the jet speed increases, while the frequency of an ET rises continuously as the speed of the jet increases. 2. The amplitude of oscillation, although very weak to the ear (because one blows very very softly), when one expresses the amplitude in nondimensional form (which approximately means if one expresses it as a fraction of its maximum possible value), is stronger than that of the normal playing regime: in the measures we made, the amplitude is about 100 times stronger than that expected for an ET.
The first is easy for anyone to verify, the second requires some experimental dedication. Now to describe what happens:
In the 'normal' playing regime, the propagation of perturbation on the jet (at a speed about half that of the jet) induces a delay of about a half period (of the fundamental of the note played). When playing WT, the jet speed is much lower, and the delay becomes about 3/2 ; 5/2 ; 7/2 etc periods, so that it arrives with the same phase delay (approximately a whole number of cycles) in all cases. In other words, the jet oscillates through half a hydrodynamic wave in the normal playing regime and through 3/2 ; 5/2 etc waves in WT: all the interest of playing WT is in finding an appropriate combination of bore resonance and hydrodynamic jet mode, by varying the fingering on the flute and the speed of the jet. In normal playing, one always maintains the the first mode of the jet and one uses different modes of the pipe.
Finally, the nondimensional amplitude en a WT is larger than in normal playing: this is an observation. The explanation could be that the amplitude is so weak that mechanisms that saturate the oscillation are different. This is vortex shedding for normal playing, and is not known for the WT.
What is the process of homogenisation? What (if anything) does it do to wind instruments?
It's difficult to be clear about this, because the vendors of homogenisation keep the details secret. However, one practitioner who charged customers money for the privelege of having him hold a vibrator near the instrument is quoted as saying that the molecules at the points of tension in the instrument are equalised or polarised. I am unaware of any double blind comparisons done to test whether the process works.
Is there any scientific background? Well, the electric polarisability of conductors (especially silver and gold) is high and that the value for hydrocarbons (including petroleum) is low. So a mixture of these components could readily be distinguished according to their polarisation in an applied field. Perhaps homogenization was the inspiration for the observation that a fuel and his money are soon parted.
Fat pipes vs thin pipes: why does the pitch of a fat pipe of an organ depend more on the blowing pressure? and
Why does a narrower tube, for the same length, favour the upper register?
It's worth discussing these questions together. The reflection at the open end of a pipe depends on the ratio of the wavelength to the radius of the pipe. This effect is important for the high resonances, and thus for the high harmonics in the sound. Further, the end effects at both ends are functions of frequency.
For the same wavelength, the reflection coefficient is higher for a narrow pipe than for a wide. The greater the reflection, the stronger the resonance (all else equal), and the smaller the band of frequencies for which it will occur. Consequently, the high resonances of a narrow pipe are also narrow: a narrower band of frequencies will cause resonance in a narrow pipe than in a wide pipe of the same length.
The frequency dependence of the end effect is important. This effect is greater for wide pipes, so in wide pipes (such as the flute rank) the higher resonances are more "out of tune" (ie less close to harmonic ratios of the first resonance). Thus the higher harmonics of the jet do not have a resonance to support their vibration, or to provide an impedance matcher to the radiation field. (The jet partials are exactly harmonic -- see How harmonic are harmonics?) So the 'string' stops on a pipe organ just use very narrow flute pipes.
As another consequence, one can 'bend' the note more on a wide pipe: one can drive it at a frequency further from its resonance.
A cone overblows at the octave, a cylinder at the 12th. What happens as we make our cone closer and closer to being a cylinder? Is there a point where it will suddenly change (if so, where), or is there an 'almost cylinder' shape which is unstable as between the two options?
The change in the frequency of the resonances is a continuous function of the cone angle. The didjeridu provides an example of a range of dofferent instruments covering quite a large range of cone angles. Some are nearly cylindrical and overblow close to a twelfth. None are ever conical, but some approximate truncated cones with varying angles. The higher the angle (for a given length and mouthpiece diameter) the lower the note of the next register. A typical didjeridu overblows about a tenth.
An interesting point: most wind instruments have harmonically related resonances, at least for notes in the lowest range. These support higher harmonics and add to the timbral brightness, loudness and pitch stability. For the didjeridu, harmonically tuned resonances are not advantageous and might in some cases be disadvantageous. The reasons are subtle, and are discussed here.
Changing the cone angle of a bore changes the mode relationships continuously. So Why doesn't the cone angle affect the overblowing interval on woodwinds?
Let's begin with the didjeridu, which is often approximately a truncated cone. The angle varies considerably among instruments. If you use a plastic pipe as a didjeridu, the hoot note (the first overblown note) of this cylindrical instrument is nearly a twelfth above the drone. Most real didjeridus are somewhat flared, however, as mentioned above, and they overblow typically a tenth.
So the question is a good one: how is it that the narrow angle of a bassoon (0.8�) and the wide angle of a soprano sax (3.5�) overblow octaves? There's a related puzzle: the wavelength of the note that these instruments play is not twice the length of the instrument, but rather about twice the length of the complete cone, i.e. (about twice) the length obtained by extrapolating the cone to a point, well beyond the mouthpiece. (See Pipes and harmonics for the sounding frequencies of conical and cylindrical pipes.)
The explanation is that woodwind instruments are not simply truncated cones. The inside the saxophone mouthpiece is not a continuation of the conical bore: there is an extra volume in the mouthpiece. Informally, we could can describe it this way: imagine a pulse of air flowing up the bore towards the reed, in both a complete cone and a real saxophone. In the saxophone, the air arrives at the mouthpiece and starts pouring into it, gradually raising the pressure. When the pressure is high enough, it forces the air back, and a reflection has occurred. Of course, the bigger the volume of the mouthpiece, the longer it takes before the pressure builds up and the reflection occurs. Meanwhile, the pulse in the complete cone is completing the longer path to the end of the bore, and then its reflection occurs. (Technically, we would say that this volume is an acoustic compliance and, using a perturbation method due to Helmholtz, this compliance flattens all of the resonances that have a pressure antinode there.) It turns out that, if you make the volume of the mouthpiece equal to the missing volume of the cone, the frequency of the first resonance is about the same, although this approximation only works for low frequencies and if the truncation is a reasonably small fraction of the total length.
A complication arises because the reed is also compliant: it takes a bit of air flow to deform it and thus to increase the pressure. So the reed's passive operation behaves somewhat like an extra air volume, in parallel with the air in the mouthpiece. (About 1 ml for a clarinet, about 3 ml for a tenor sax. Soft reeds and a more relaxed bit both give greater compliance, so you then have to push the mouthpiece in and reduce the air volume to get the instrument and its octaves in tune.)
For the double reeds, the extra volume inside the reed is not very large, but neither is the truncation. Further, the compliance of the reed itself is more significant, and the viscothermal losses near the reed complicate the tuning.
Why does the clarinet produce even harmonics?
The reeds of clarinet and saxophone are fairly similar. In general, the vibration of the reed produces both odd and even harmonics for both instruments. For notes in the lowest range of the clarinet, however, the resonances of the bore fall near 1, 3, 5, etc times the fundamental frequency, and so are more effective at radiating odd harmonics than even harmonics.
So the even harmonics are weaker for these notes. For notes in the lowest range of the saxophone (or flute, oboe etc), the resonances of the bore fall near 1, 2, 3, 4, etc times the fundamental frequency, and so are effective at radiating both odd and even harmonics.
For notes in the middle and high range of both instruments, there is a resonance near the fundamental, but not consistently near any of the harmonics, so there is no pattern of even or odd harmonics. See Open and closed pipes (flutes vs clarinets) for more discussion.
Why does a flute not need a bell?
One obvious answer is that quite a lot of the radiation from a flute comes from the embouchure hole. Other woodwinds and brass don't have open embouchure holes.
Next, pull the bell off an oboe or clarinet and you'll hear that, except for the tuning of the lowest few notes of the bottom two registers, it doesn't make a big difference to those instruments.
The main purpose of the bell on a woodwind is to provide for those notes a cut-off frequency (see the pages on individual woodwind instruments for a discussion) like that produced for the other notes by the array of open tone holes. The flute's cut-off frequency is already rather high, because of the relatively large holes. So it is less necessary. (Incidentally, I have seen a strange bass flute with a bell. A bass flute needs as much radiation as it can get!)
In woodwinds, how do you get the higher resonances in tune? Playing the whole-tube note of let's say an oboe, presumably the partials are not perfectly harmonic because the flattening effect of the reed has greater effect on the higher frequencies. And the end correction will be different for the higher frequencies. And the chimneys of closed holes also affect lower and higher frequencies differently?
That's a tricky question, involving lots of compromises, and makers have answered it by changing the shape slightly in an evolutionary way. Note that the instruments are never exactly cylinders or simple cones. The taper in the head of the flute and the volume between cork and embouchure hole are there to improve tuning between registers. The extra volume in the mouthpieces of saxophones compensates for the fact that they are truncated cones, rather than complete cones.
What harmonics are present when you jump a register? Playing the high register note, will you produce exactly the same set of partials, only minus the fundamental? Or are you producing a new set of partials whose lowest element is not necessarily exactly the same as the second partial of the low register note?
In the higher register, the reed or lips vibrate at the fundamental frequency of the note played. This vibration is not purely sinusoidal, so they produce higher harmonics of that new fundamental frequency. This means that only some of the resonances of the instrument may be excited. eg, for the flute in the second register, all of the resonances of the lower register harmonics are available, but only the even ones are used. For the clarinet, only every third one is used. Don't take my word for it, see the impedance curves and sound spectra for individual notes on the flute and clarinet. See also How harmonic are harmonics?
Why does an oboe jump registers more easily than say a bagpipe chanter?
The oboe reed is directly influenced by your lips and also by your vocal tract.
On a woodwind, why do the 'short tube' notes bend more easily than the 'long tube' notes?
If you look at the impedance curves and sound spectra for individual notes on the flute and clarinet, you'll see that long tube notes have several sharply-tuned resonances that fall at harmonics of the note played. Short tube notes have fewer resonances that fall in tune with the harmonics, and the resonances are in general broader. So in bending a long tube note, you are working against several sharply-tuned resonances.
When you jump a register, are the reeds (or lips) moving in the same mode, or do they get modes with a node, too? Are the reed blade(s) moving roughly the same way as for the lower register, only at twice the frequency, or are the reed blade(s) also moving in mode 2 fashion - ie like a plate with a displacement node roughly in the middle?
Your first answer is correct. When you go across the break between registers, there is only a small modification in the lip or reed motion (apart from the frequency). The small difference is due to the presence of more resonances for the long tube note, as discussed in the preceding question. See also How harmonic are harmonics?
On saxophone and clarinet, is there a correct note that the reed and mouthpiece (alone) should sound?
One might answer: If you can play in tune, with a good sound and you are comfortable, who cares what note comes out when you blow the mouthpiece? Of course, not all of us do satisfy those conditions, and some teachers use the mouthpiece pitch exercise as a diagnostic. So, why might this exercise have a diagnostic value? There is an approximate answer to this question.
In a simple but very useful model probably originating with Benade, the reed of the sax or clarinet is loaded by the acoustic impedance of the bore Zbore in series with that of the player's vocal tract Ztract. To a rough approximation, the sax or clarinet plays at a peak in Zbore + Ztract. You may have learned that, in electricity, we often describe a real generator or battery as an ideal source together with a finite internal resistance or internal impedance. In much the same way, we can conceptually divide the reed into the reed generator (the idealised component that converts breath into sound) and the reed's own passive impedance Zreed. With a little algebra, you can see that this reed generator is loaded by the parallel combination of Zreed and Zbore + Ztract, which we'll call Z||. To a rather better explanation, the instrument plays at one of the strongest peaks in Z||. (I give more explanation in this paper.)
Now the reed is flexible, so its passive response at low frequencies is to blow out or into the mouthpiece with positive or negative pressure in the mouthpiece. The volume of air inside the mouthpiece is compressed or expanded by positive or negative pressure in the mouthpiece. (Technically, this means that both are largely compliant at low frequencies.) So the effective volume of the mouthpiece is its real volume, plus an extra bit due to the presence of flexible reed. (The effective volume of the reed is about 1 ml for a clarinet and several ml for larger saxophones, and it is smaller for harder reeds and tighter embouchures but larger for soft reeds and relaxed embouchures.)
(Also to a reasonable approximation, the tuning of the resonances requires that the effective volume of mouthpiece (including the contribution from the reed) should replace the volume of the truncation of the conical bore. That's another (but related) story.)
The instrument maker determines Zbore. Your bite and the reed hardness largely determine Zreed. Your mouth configuration determines
Ztract (which is usually small, except when bugling, pitch bending or playing altissimo).
Zreed and Ztract also largely determine the frequency at which the mouthpiece plus reed will play, though the pitch may be high enough that we need to worry about the (inertive) contribution to Zreed from the mass of the reed and that of the air in the mouthpiece (the inertive and compliant terms are approximately equal at the frequency of a reed squeak).
So, putting all of that together, if you have adjusted Zreed and Ztract so that Z|| has peaks at a particular frequency for a particular fingering, then the
mouthpiece will play a particular frequency. Or, to put it the other way round: if you have adjusted Zreed and Ztract so that the
mouthpiece plays a particular frequency, Z|| will have peaks at a particular frequency for a particular fingering.
(This frequency could be different for different mouthpieces.)
One more step. I'm told that a player called Santy Runyon told a story about driving a saxophone with an electric gadget (whose exact details I don't know) that acted as a regenerative source, somewhat like a reed, except that one could readily vary its natural frequency, whereas changing the mass and stiffness of the reed is more difficult. If we knew the details of that generator, we could probably draw analogies. So, adjusting one of its component values would be like, say, changing bite or reed hardness. Even though I don't know the details of the electronic gizmo, I think that the analogy is far from perfect: for instance, there would probably be no analogy for Ztract. It is quite plausible, however, that some particular values of its parameters covered different parts of the instrument's range better or more completely than others, for fairly similar reasons.
Inside the mouth of saxophonist or clarinettist, is there a pressure node or antinode near the reed?
Nodes and antinodes apply to standing waves, not to travelling waves. When the vocal tract resonance is tuned to the note being played (as in bugling, pitch bending and altissimo playing), the wave in the mouth is a strong standing wave and the reed is very near a pressure antinode. In ordinary circumstances, however, that wave is not usually a standing wave, so it doesn't have clear nodes or antinodes.
Why are clarinet tone holes different sizes?
As background, the flute has tone holes that are mainly the same size: the three register/trill holes are small, but all the tone holes are the same size, with the exception of the three or four on the foot joint, which are slightly larger.
There are several reasons. The clarinet is not cylindrical. Most of the lower joint is flaring and so, with the larger bore diameter, the holes have bigger diameter. But there are still variations in the cylindrical part. I think that the reason is this: if one can change both the size and the position, one has twice as many parameters to vary in order to get the instrument in tune.
How does an ocarina work? How can such a small instrument produce such a low pitch?
An ocarina is an example of a Helmholtz resonator. Think of blowing over the neck of a bottle: the air in the neck of the bottle is a mass (strictly an inertance) that oscillates on the 'spring' (strictly a compliance) of the air inside the bottle. The ratio of compliance to inertance determines the frequency, but there is no simple relation between the instrument size and the wavelength it produces.
On a ocarina or similar instruments, tone holes can be added to change the frequency of the resonance. The tone holes in the ocarina are also inertances that can also oscillate on the compliance of the enclosed air. Opening successive tone holes puts these other inertances in parallel with that of the blow hole. The total inertance of two or more inertances in parallel is less than that of any one of them, so the compliance/inertance ratio is larger and the pitch is higher.
What is mouthpiece clocking on a brass instrument? And (how) does it work?
This refers to comparing the performance of a brass instrument for different rotational positions of the mouthpiece in the receiver (the input) of the instrument. (It's described here.) If the mouthpiece and receiver both had perfect rotational symmetry, one would expect this to make no difference at all. But how symmetrical are they? Remember when you dropped your mouthpiece? and when that idiot knocked over your instrument? For a slightly asymmetric mouthpiece and receiver, there will likely be (at least) one angular position that gives the best seal. 'Clocking' is then the process of finding that position. (If the mouthpiece and input are approximately elliptical, then the positions after rotations of approximately 180° might behave similarly.) Try it with a new and a slightly battered mouthpiece and see if you agree.
Questions related to singing
How can people sing two notes at the same time?
Harmonic singing. Basically, they sing one rather low note, and then use a resonance in the vocal tract (which must be quite strong and narrow in frequency)
to enhance the production of just one high harmonic of the low note. When it is much stronger than nearby harmonics, we notice it as a separate note. This question is also a bit subtle. We made some measurements of the frequency response of the tract and put an explanation on the page Harmonic singing.
It is also possible to hum and to whistle at the same time. This allows greater independence between the two notes.
Can a soprano shatter someone's spectacles by singing a loud, high note?
The answer is no, but the question is not as bizarre as it sounds. Consider the phenomenon of resonance. Some systems, such as a child on a swing or a wine glass, can vibrate and store energy of vibration at a particular frequency, their resonant frequency. I give my nephew on the swing a gentle push, then another, then another... after 20 pushes he is flying three metres in the air, which is far higher than I can throw him. The energy of all the successive pushes has been stored in the vibration.
Some wine glasses can ring spectacularly at a particular frequency: give them a flick and a nearly pure sine wave sounds. Suppose that the singer sings this frequency (it falls in the soprano range, and operatic sopranos are good at concentrating lots of energy in the fundamental frequency). A little sound energy gets stored in the glass with each vibration cycle and eventually a substantial amount of energy is stored in the glass, causing oscillations of large amplitude.
If you use very high acoustic power from an amplifier and loudspeaker in a confined space, it is possible to break a wine glass. This is described by W.C. Walker in "The Physics Teacher", 1977 (Vol 15, pp. 294-296). A manufacturer of recording media once used a film clip of a glass being broken by highly amplified sound in an advertisement, and this may be the origin of the now widespread comic cliché of glass breaking when a singer sings.
Can a singer shatter a wine glass this way? Under normal conditions, I doubt it. The power output of a singer is less than 1 Watt. Of this, only a tiny fraction impinges on a wine glass in the auditorium, and, in most situations, the geometry is such that the wine glass is not strongly coupled to the sound wave. Further, the wine glass can lose energy both internally and by re-radiation, or just rattling. In any wine glasses I have touched, the resonance is just not that good. Mind you, I don't mix with the class that has really fine glassware!
Late news. I was tipped off that a wine glass was shattered by an unamplified singer in a session of Mythbusters TV show. I've not seen the show, but the transcript suggests that the glass was held very close to the singer's mouth. This geometry could couple a substantial fraction of the singer's power into the glass. So don't expect it to happen under normal voice - wine glass geometries!
As for spectacles, they hardly ring at all: the frames and attachments are too good at removing energy. Find a pair, give them a flick and see.
However, resonance can do some much more spectacular things. A bridge constructed across Tacoma Narrows, Washington, had strong resonances. In November 1940, the wind excited these resonances so strongly that the bridge fell. The film of the event is shown to first year physics and engineering students around the world. Videos can be found on line.
Our page explaining how sopranos concentrate energy in the fundamental is here
What is a formant?
The simple answer is that a formant is a broad peak in the sound spectrum. In writings about the voice, however, it is more complicated, and the question has potentially as many as three different answers. The page Formants: what are they? gives a discussion of the different meanings of this term for voice studies.
What is a break in a voice?
The vocal folds (often misleadingly called vocal cords) can vibrate in two or more* qualitatively different ways. One of these, called M1 for mechanism 1, involves the vibration of much of the muscle in the folds. In M2, very little muscle vibrates. M1 is used by most men over most or all of their speaking and singing range. For a man, M2 is the source of falsetto. For women, M1 correspond to what is often called the chest voice, and M2 to the head voice. The break refers to the transition from one to another. It is difficult to do this smoothly in a glissando, and difficult to hide it if one sings M1 for one note and M2 for the next. This site shows videos of the different mechanisms. We discuss this in more detail in 'Introduction to voice acoustics'.
* There are at least two others, used less frequently. Mechamism zero, sometimes called creak voice or strohbass, is rather like mechanism 1, but is aperiodic and has no clear pitch. Mechanism 3, used by coloratura sopranos and others, is called the whistle voice. It involves only little motion by the vocal folds.
Questions related to electronic instruments, loudspeakers etc
Why are some 100 Watt guitar amplifiers so much louder than others?
Some 100 W amplifiers (ie the electric part) actually can output 100 W of electrical power. Many output rather less (look for give-away lines such as "peak-to-peak", "peak music power" etc). If you multiply the maximum range of the voltage variation by the maximum range of current variation, you get a value of power that is eight times larger than the maximum possible power that the amp can deliver for a short time, which may in turn be larger than the power it can deliver for a sustained period. See RMS and power for details.
A loudspeaker rated at 100 Watts RMS is claimed to be able to absorb 100 W of electrical power without damage. It says nothing about the sound power output. Loudspeakers are typically about 1% efficient, but the value varies considerably: some are much more efficient than others. (See Why are loudspeakers so very inefficient?) Now the logical thing would be for all makers to agree to print the value of the sound power output. This is unlikely to happen. First, it is harder to measure. Second, the manufactures are unlikely to want to sell a 1 Watt amplifier with a mass of tens of kg and a price of hundreds of $.
In the design of amplifiers, and even more so in loudspeakers, one often has to make a compromise between efficiency and fidelity (and other parameters such as weight and cost). In hifi amplifiers distortion is considered as a disadvantage (although some people prefer the distortion produced by valves to a sound that doesn't have this distortion). In guitar amps, distortion is often regarded as a good thing. For instance, the most easily produced harmonic distortion is clipping, which makes a sound brighter and harsher, and also produces sustain. Both are considered desirable by some guitarists. So different manufacturers make different compromises between fidelity and efficiency.
What is the orientation of the magnetic field in a loudspeaker?
Radial. This is shown in a page on loudspeakers in this link.
What is the effect of wall materials on a loudspeaker enclosure? Should they be rigid?
Acoustic suspension of speakers and ports in enclosures both rely on the "springiness" of the air. Technically, one normally talks of the compliance, inversely proportional to the spring stiffness. The compliance of the air is in parallel with that of the walls of the enclosure. This is because, when extra air goes in and the air is compressed, the walls are bulged out a little, so the air is less compressed than if the walls were completely rigid. Real walls are not infinitely rigid and compliant (deformable) walls slightly add to the compliance of the air or in other words make it a less stiff spring.
There is a resonant frequency associated with this combined springiness. If we are talking about a port, then it is a Helmholtz resonance: the mass of air near the port is suspended on the 'spring' of the air & box. One can find this resonance by singing or playing a note nearby and listening, or putting a microphone inside. See our web page Helmholtz resonance.
If you have a loudspeaker in a sealed enclosure, then the mass of the cone is suspended on the combined spring of its mechanical support (the ridges around the edges), the air and the walls. So the resonant frequency is different.
How can you tell whether the wall compliance is important? Actually quite easily. The obvious experiment might seem to be to pump air in and measure the deformation but several problems (leaks, thermal, measurement) would make this difficult. Instead, here is the experiment I recommend:
1) Measure the Helmholtz resonance of your enclosure in the normal condition, as described above.
2) Now bury the enclosure in sand, but keep the sand away from the port, so that it doesn't block radiation from it (technically : doesn�t much reduce the solid angle of the radiation field). Now measure the Helmholtz resonance of the enclosure. The sand is massive enough that its inertance reduces the compliance of the enclosure close to zero. You now have the "true" Helmholtz resonance. Without the sand, you have the Helmholtz resonance due to the air and the parallel compliance of the walls.
Take the ratio of the frequencies, square it and subtract 1. This is (roughly) the ratio by which the walls have increased the compliance.
Does the finite compliance of the wall mean that different materials have an effect? Qualitatively, the answer is yes. However, my prediction is that, for most commercial enclosures, it will change the Helmholtz resonance by less than 10%. Consequently, the difference in material will be small. However, I'll be interested to hear any experimental results.
A similar experiment is sometimes done on violins and guitars, for the same reason. In those cases, it has only a modest effect. You might think that, because these objects have much thinner walls than your enclosures, this means that the effect must be much smaller in the enclosures. Yes, but they are stiffened by their curvature and by internal braces (g) and bass bar & soundpost (vln). This is explained in more detail in our pages on guitar and violin.
If anyone decides to do the experiment described above, you might like to write to me with the results (and pics?), which we can then incorporate here, with attribution, of course.
Where can I get a Fairlight CMI (computer musical instrument)?
About 1% of the electrical energy input to a loudspeaker is converted into sound. So, if your loudspeaker is rated at 20 Wrms, you might expect to be able to output as much as 0.2 W of sound power. (Which is very loud indeed! See What is a decibel? for some calculations.) But why is it inefficient?
Because of its low density, the air in front of a loudspeaker diaphragm is moved, rather than compressed, by the loudspeaker. How much air is moved? Without doing a difficult calculation (and justifying the omission because William Strutt has already done it), we should expect that the equivalent volume is of the order of speaker area A times the radius r of the speaker. If the speaker is in a very large plane baffle, the equivalent volume turns out to be 0.85.Ar. Let's take a speaker of 100 mm radius, so the air that we have to accelerate has mass
ρ.π.r3 = 0.85(1.2 kg.m−3)π(0.1 m)3 = 3 g.
There's also the air inside the speaker box, in which there is both acceleration and compression, but this doesn't contribute to the sound outside.
The trouble with loudspeakers is that a diaphragm 200 mm in diameter, and the coil of wire needed to move it, and the support for it, all together have a mass much greater than 3 g. So, in order to move 3 g of air, we have to move many g of hardware. (See Loudspeakers on Physclips.)
So your next question will be 'How to shift lots of air with only a small diaphragm?', to which the answer is a horn. Put the loudspeaker at the small end of a long, smoothly diverging horn and, at the output end of the horn, we shift a big cross section of air. The inconvenience is that, at low frequencies and thus long wavelengths, the horn needs to be very long.
Why is the fidelity of headphones usually so much better than that of (ordinary) loudspeakers?
An enclosed headphone has a small volume of air that doesn't go anywhere so, for wavelengths rather longer than the size of the the enclosed volume, the air in the headphone is compressed rather than accelerated. In the absence of sound, the air in the headphone has constant atmospheric pressure PA and volume V so, to compress it by −ΔV, we require a pressure p = −PA(γ.ΔV/V), where γ, the adiabatic factor, is about 1.4 for air. So the proportional volume changeΔV/V required to produce a sound pressure amplitude of 1 Pa (a very loud sound) is only (1 Pa/100 kPa)/1.4, which is seven parts in a million.
In acoustical terms, we say that the enclosed volume of air is a (low) compliance, which has a very high impedance at audible frequencies. This contrasts with the very low inertance and thus low impedance of the radiation field being driven by the normal loudspeaker enclosure. The loudspeaker itself has a high output impedance, and so it is much it is much easier to drive a small compliance than a small inertance. See Sound wave equation and related pages on Physclips for more details.
As of June
2005, relativity is 100 years old. Our contribution is Einstein Light: relativity
in brief... or in detail. It explains the key ideas in a short multimedia
presentation, which is supported by links to broader and deeper explanations.



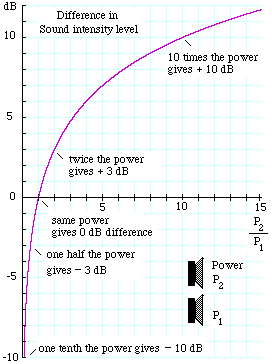
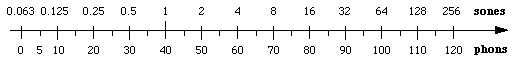
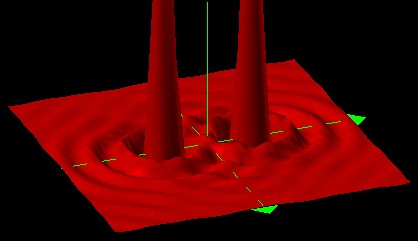 Now imagine that
we have two identical, linear amplifiers and speakers, and we'll forget about reflections from walls, floor etc. We put the same signal into the inputs of both. Now each amplifier is producing the same amount of electrical power, so the output sound power is only doubled. On average, the intensity in the sound field is only doubled. Let's consider just a single sine wave (or, if you like, one frequency component of the sound). If your ear is equidistant from the two speakers, then the two pressure waves will add in phase (constructive interference), so the sound pressure at your ear will be twice as great, so you'll a level 6 dB higher when the second amplifier is turned on. However, if you are half a wavelength further from one speaker than from the other, then two pressure waves will add one half cycle out of phase (destructive interference) and the sound pressure will be zero. So the sound intensity is four times as great in some places, zero in others, and intermediate values in most places. Integrate this over all space and the total power is only doubled.
Now imagine that
we have two identical, linear amplifiers and speakers, and we'll forget about reflections from walls, floor etc. We put the same signal into the inputs of both. Now each amplifier is producing the same amount of electrical power, so the output sound power is only doubled. On average, the intensity in the sound field is only doubled. Let's consider just a single sine wave (or, if you like, one frequency component of the sound). If your ear is equidistant from the two speakers, then the two pressure waves will add in phase (constructive interference), so the sound pressure at your ear will be twice as great, so you'll a level 6 dB higher when the second amplifier is turned on. However, if you are half a wavelength further from one speaker than from the other, then two pressure waves will add one half cycle out of phase (destructive interference) and the sound pressure will be zero. So the sound intensity is four times as great in some places, zero in others, and intermediate values in most places. Integrate this over all space and the total power is only doubled.
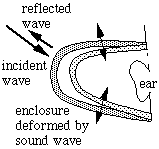
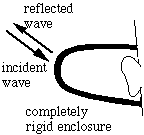

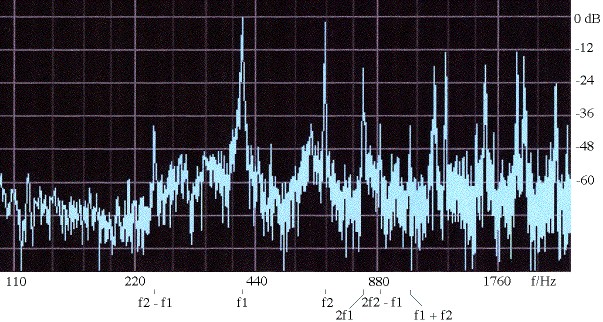 The strong Tartini tone that we sometimes hear is usually generated in the ear. In the case of the two recorders (above), there is no vibration in the air at the difference frequency. However, when two notes are played simultaneously on the same instrument -- as played here on a violin by John McLennan -- it is possible to produce a difference tone via non-linearities in the instrument. This is explained in more detail in
The strong Tartini tone that we sometimes hear is usually generated in the ear. In the case of the two recorders (above), there is no vibration in the air at the difference frequency. However, when two notes are played simultaneously on the same instrument -- as played here on a violin by John McLennan -- it is possible to produce a difference tone via non-linearities in the instrument. This is explained in more detail in 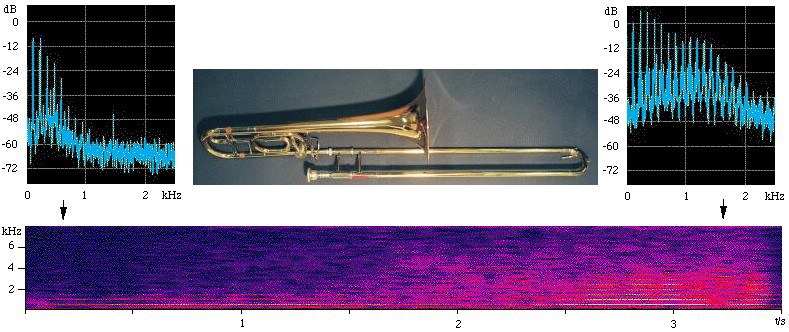
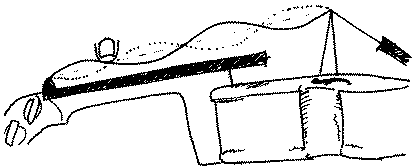
 However, there is more to the story than this. First, mass producing some components makes a big difference to the price of cheap instruments, a useful difference to mid-range instruments, and very little to high priced instruments. If you are paying a maker's wages for a month or two to make you an instrument, you might well think about paying for an extra day to carve some components that s/he could buy ready made. Second, there is the tradition: it is still possible for one person to make (nearly all of) a violin in a simple workshop, and keeping this tradition alive is appealing in an age in which, for example, cars and computers are no longer thus made. (The photo shows the celebrated maker of more than 500 instruments
However, there is more to the story than this. First, mass producing some components makes a big difference to the price of cheap instruments, a useful difference to mid-range instruments, and very little to high priced instruments. If you are paying a maker's wages for a month or two to make you an instrument, you might well think about paying for an extra day to carve some components that s/he could buy ready made. Second, there is the tradition: it is still possible for one person to make (nearly all of) a violin in a simple workshop, and keeping this tradition alive is appealing in an age in which, for example, cars and computers are no longer thus made. (The photo shows the celebrated maker of more than 500 instruments